BacklogのSREを担当しているmuziです。
今回の記事では、ヌーラボにおけるSREの活動事例として、Backlogの課題検索機能のリプレイスプロジェクトについてご紹介します。
このプロジェクトでは、SREと開発者がチームを組んで、要件定義からリリースまで行いました。その結果、Backlogを構成するサーバ同士が疎結合になり、将来的なマイクロサービス化に向けた足がかりを作ることができました。
歴史の長いプロダクトにありがちな技術的負債への取り組みの一例として、みなさんの参考になれば幸いです。
目次
リプレイスプロジェクトの背景
Backlogの課題検索機能
最初に、このリプレイスプロジェクトの背景として、Backlogの課題検索機能についてご紹介します。
課題検索機能とは、Backlogの「課題」ページで利用できる検索機能のことです。件名や詳細に対するキーワード検索に加えて、プレミアムプラン以上のプランではカスタム属性(ヘルプページ)に対する検索も利用できます。
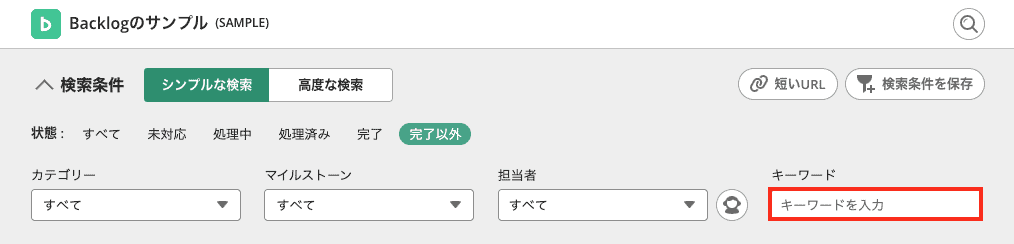 件名や課題に対するキーワード検索
件名や課題に対するキーワード検索
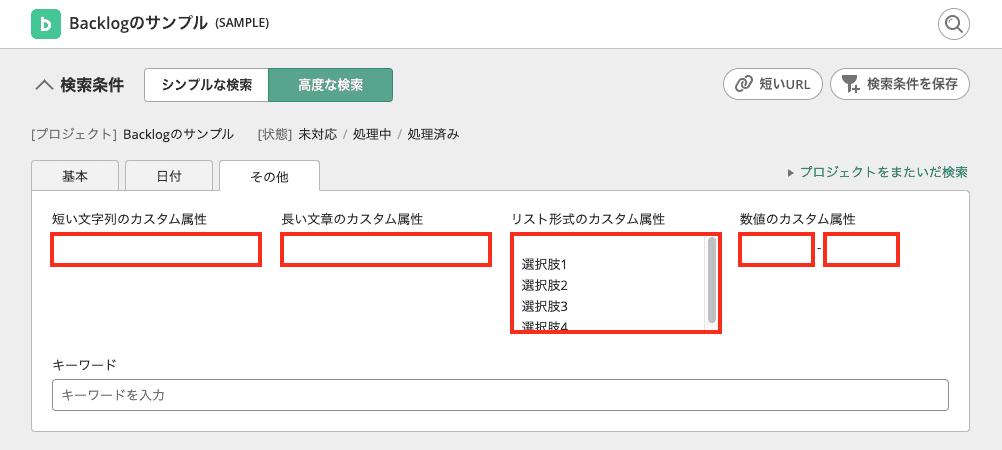 カスタム属性に対する検索
カスタム属性に対する検索
従来の実装
従来の課題検索機能は、全文検索ソフトウェアのLuceneを用いて実装されていました。そのシステム構成を以下に示します。
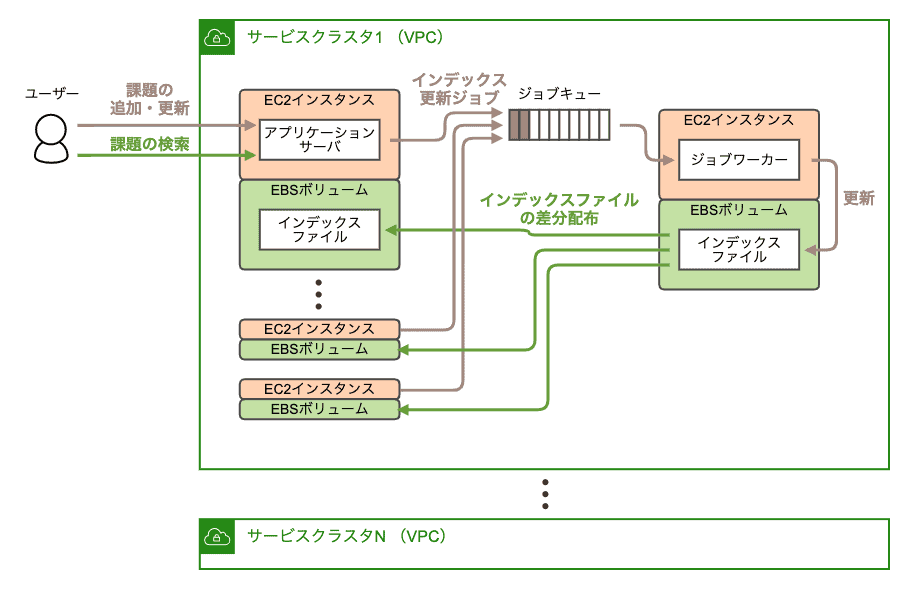 従来の課題検索機能のシステム構成
従来の課題検索機能のシステム構成
まず、Backlogの各サービスクラスタに、Luceneのインデックスファイルを作成するためのサーバ(以下、インデキシングサーバ)が1台存在します。このサーバは、インデックス更新ジョブをジョブキューから取得し、その都度Luceneのインデックスファイルを更新します。
インデキシングサーバ上には、インデックスファイルの変更を監視するための内製ソフトウェアが動作しており、rsyncを使って変更内容(差分)をすべてのアプリケーションサーバに配布します。
各アプリケーションサーバは、アタッチされたEBSボリューム上にあるインデックスファイルを参照して、課題を検索します。
このシステム構成には、検索時にネットワーク通信が発生しないというメリットがあります。また、Backlogのユーザー数が少ない頃には、このシステム構成で問題なく動作していました。しかし、ユーザー数が増え、それに伴ってアプリケーションサーバの台数も増えるに従って、いくつかの課題が生じてきました。
従来の実装における課題
従来の課題検索機能の実装には、大きく分けて4つの課題がありました。
- スケーラビリティ
- 可用性
- ハードウェアコスト
- 運用コスト
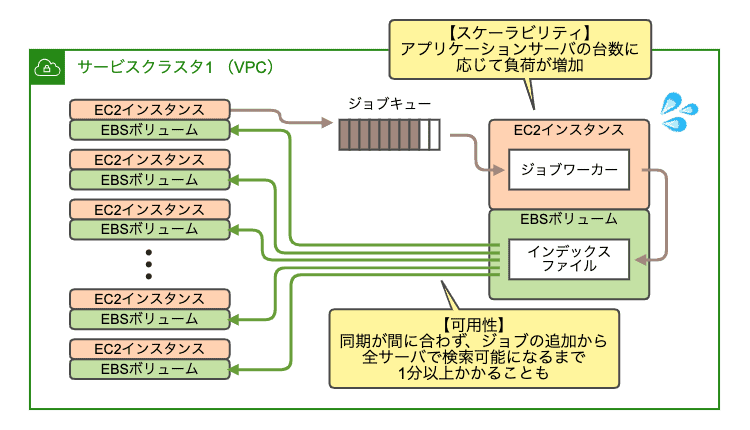 従来の実装における課題
従来の実装における課題
スケーラビリティ
アプリケーションサーバにインデックスファイルを設置する必要があるため、アプリケーションサーバのEC2インスタンスを構築しても、ユーザーから利用可能になるまでにはそこから更に数時間かかりました。つまり、動的なスケールアウト・スケールインが難しい状態でした。
また、アプリケーションサーバの台数に応じてインデキシングサーバの負荷(rsyncの負荷)が上がるため、アプリケーションサーバを増やす際には、インデキシングサーバのキャパシティプランニングが必須でした。
可用性
インデックスファイルの同期に時間がかかるため、課題を作成・更新してから、実際にその課題を検索できるようになるまでに1分以上かかることがありました。
また、この同期は時々失敗することがあり、それが原因でユーザーからの検索リクエストが失敗することがありました。この検索失敗に関しては、ユーザーからサポートに時々お問い合わせを頂いておりましたが、根本解決できない状態が続いていました。
また、インデキシングサーバが冗長化されていないため、この大本のインデックスファイルが破損した場合、復旧に時間がかかる状態でした。
ハードウェアコスト
BacklogはAWS上で動作しているのですが、インデキシングサーバとアプリケーションサーバの間でファイルを同期するための、AZ間通信の費用が徐々に高額になっていました。
また、各アプリケーションサーバに、このインデックスファイルを設置する必要があったため、巨大なEBSボリュームをアタッチしていました。これらの費用も高額になっていました。
運用コスト
最後に、インデックスファイルの同期に失敗した場合、対象のアプリケーションサーバを特定したうえで、手作業での復旧作業が必要でした。
リプレイスプロジェクトの概要
プロジェクトの立ち上げ
昨年(2019年)の前半から、ヌーラボのSREは、各プロダクトから独立した「SRE課」という部署に属しています。このSRE課には、運用を担当するSREに加えて、運用は担当せずに改善のための開発のみを担当する開発者も所属しています。
今回のリプレイスプロジェクトでは、このSRE課に所属するSRE 1名と開発者1〜2名(プロジェクト前半は2名、後半は1名)の小さなプロジェクトチームで、新しい課題検索機能を開発しました。自分は、SRE兼プロジェクトマネージャーとして参加しました。
プロジェクトの目的
プロジェクト開始時には、この機会にLuceneのリプレイス以外の改善も行うかどうかなど、プロジェクトの範囲についてメンバー間での認識が揃っていませんでした。そのため、インセプションデッキを用いて、プロジェクトの目的を明確にしました。
プロジェクト開始時のインセプションデッキから、目的についてのページを引用します。
 プロジェクトの目的
プロジェクトの目的
SRE課では、サービス改善のサイクルを早めるために、開発チームごとの責任範囲を明確にし、開発から運用まで、その開発チームの判断で動きやすくすることを目指しています。そのための手段として、マイクロサービス化も将来の選択肢の一つとして検討しています。
マイクロサービス化を目指す理由については、過去のブログ記事(SREは大規模なリプレイスプロジェクトで発生した様々な問題にどう取り組んだか【Backlog Play 化プロジェクト】)でも触れました。興味のある方はこちらもご参考ください。
課題解決のためのアプローチ
プロジェクトの目的を明確にし、さらにトレードオフ・スライダーで「既存機能の維持」、「高品質」および「短期間でのリリース」を重視することを決めました。
 新しい課題検索機能のトレードオフ・スライダー
新しい課題検索機能のトレードオフ・スライダー
このトレードオフ・スライダーに基づき、問題解決のためのアプローチを以下のように定めました。
- 開発スコープの限定(既存機能を実現し、早急にリプレイスすることを最優先)
- スケールアップ可能なElasticsearchクラスタの導入
- マネージドサービスの利用
プロジェクトの進め方
要件定義〜設計は全員で分担したのち、その後のElasticsearch周りの設計・構築・運用設計はSREが担当し、アプリケーションサーバやbulk indexingツール(後述)の実装は開発者が担当しました。コードの修正はアプリケーションサーバに詳しい開発者に一任して、SREはコードレビューのみ参加しました。
1スプリントを2週間としてスクラムのイベント(朝会、スプリントプランニング、スプリントレビュー)を取り入れ、これらのイベントにはマネージャー1名およびスクラムマスター1名にも参加してもらいました。
しかし、今回は段階的なリリースが難しい機能だったため、最終的にはほとんどウォーターフォール型の開発になりました。開発は約5ヶ月で完了し、おおよそ、要件定義・設計・実機検証に5スプリント、実装に3スプリント、テストに2スプリントでした。新旧の実装を約2ヶ月並行稼動させたのち、新しい実装に一本化しました。
以下では、新しい課題検索機能について詳しくご紹介します。
新しい課題検索機能
システム構成
新しい課題検索機能は、ElasticsearchのマネージドサービスであるAmazon Elasticsearch Service(以下、Amazon ES)を用いて実装しました。そのシステム構成を以下に示します。
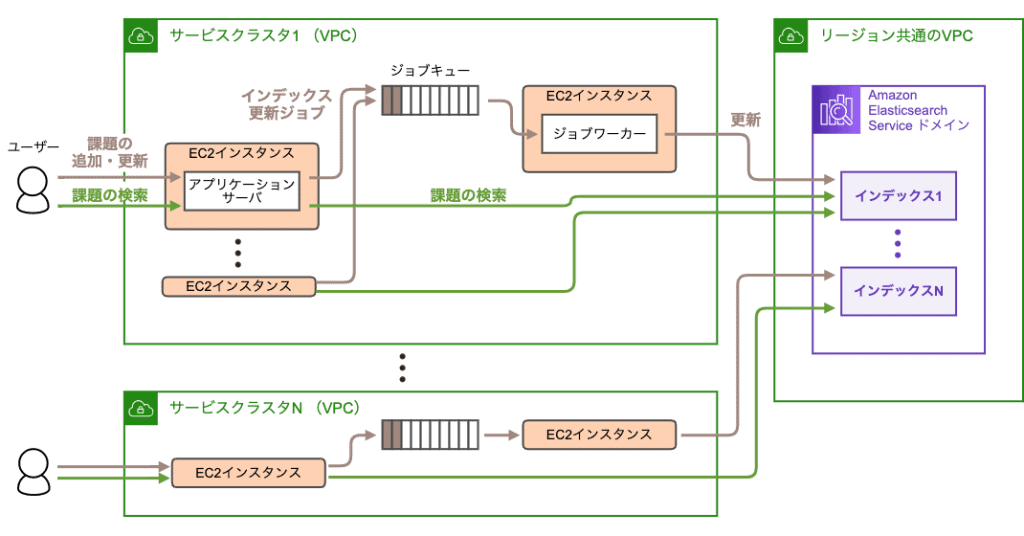 新しい課題検索機能のシステム構成
新しい課題検索機能のシステム構成
全文検索エンジンとしてはElasticsearchとSolrが有名ですが、今回はAmazonやElasticがマネージドサービスを提供しているElasticsearchで検討をはじめました。
マネージドサービスではAmazon ESとElastic CloudのElasticsearch Serviceを比較しました。Elastic Cloudのほうが多機能でしたが、最終的に、以下の理由からAmazon ESを採用しました。
- 今回の機能要件および性能要件は、Amazon ESでも満たせたこと
- ヌーラボでは元々AWSを使っているため、課金をAWSで一元化できたこと
- ヌーラボはAWSのエンタープライズ契約を行っているため、Amazon ESに詳しいテクニカルアカウントマネージャー(TAM)の協力を得られたこと
ネットワーク遅延を考慮して、AWSリージョンごとにElasticsearchクラスタ(Amazon ESの用語ではドメイン)を構築しました。これらのクラスタは開発環境も含めてすべてTerraformで構築しました。
セキュリティ上の理由から、ElasticsearchのクラスタはVPC内に設置しました。また、AWSを署名必須にし、IAMロールで認証・認可を行うようにしました。
それに加え、インデックス単位の認証・認可を厳密に行うために、rest.action.multi.allow_explicit_indexをfalseに設定しました(デフォルトはtrue)。この設定を有効にするとKibanaを使えなくなるため、awscurlコマンド(AWS署名に対応したcurl)を用いた運用手順を整備しました。
awscurlコマンドの採用理由については説明すると長くなるため、詳細に興味のある方は、私の書いた個人ブログの記事(Amazon Elasticsearch Service の認証・認可に関する面倒くさい仕様をなるべくわかりやすく説明する)をご参照ください。
アプリケーションサーバの実装
アプリケーションサーバからElasticsearchクラスタへのアクセスにはelastic4sを用いました。このライブラリはAWS署名に対応しており、IAMロールを用いる限り、開発用のローカル環境と、EC2インスタンス上の動作で、設定変更などは必要ありませんでした。
インデックス定義は、Luceneのときとほぼ同じものを採用しました(Elasticsearchも内部的にはLuceneを利用しています)。ただし、従来の課題検索機能ではBacklogのスペース(契約)ごとにインデックスを作っていましたが、新しい課題検索ではサービスクラスタごとに1個のインデックスを作るようにしました。これは、Elasticsearchのインデックス数が多すぎるとヒープメモリの枯渇が起こるためです。
クエリの定義も、Luceneのときとほぼ同じものを採用しました。ただし、ネットワーク遅延による影響を極力減らすために、filter_pathパラメータを使用して、最低限必要なフィールドのみを取得するようにしました。
実装面で工夫した点としては、大量の課題をインデキシングするための専用のツール(bulk indexingツール)を新たに開発しました。これはElasticsearchのBulk APIを呼び出すことで、大量の課題を高速にインデキシングできるツールです。
本番環境のデータでテストを繰り返し、並列数などをチューニングして速度改善を行いました。その結果、仮に、万が一、すべてのインデックスが壊れても、約6時間で復旧できる状態になりました(Backlogで一番大きなサービスクラスタの場合)。これは、従来の課題検索機能では1日以上かかる作業でした。
その他の改善
その他の改善としては、大多数のユーザーに影響が出ない範囲で、データサイズの上限を見直しました。
要件定義中に、特定のお客様でインデックスサイズが極端に大きく、検索が遅い、という問題が見つかりました。そのため、既存の課題のデータサイズを調査し、そのうちの99.95〜99.99パーセンタイルが収まる範囲で、データサイズの上限を変更させていただきました(リリースブログ)。
上限を現実的な範囲に変更することで、性能テストを十分に行うことができ、結果的にサービスの安定稼働につなげることができました。
旧システムからの移行
本番サービスを止めることなく移行を進めるために、検索機能もインデキシング機能も、設定ファイルで新旧を切替可能にしました。
移行作業は、インデキシングの並行稼動 → 検索の切り替え → インデキシングの旧実装停止、の順に行いました。これをサービスクラスタ別に実施しました。少しでも問題が発生したら、旧機能に戻しました。
サービスクラスタ1個あたり3〜4週間の並行稼動を行い、全体で約2ヶ月で完了しました。
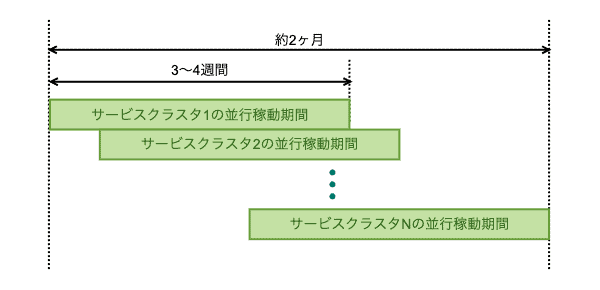 移行スケジュールのイメージ
移行スケジュールのイメージ
新しい課題検索機能の導入効果
スケーラビリティ
インデックスファイルの同期が不要になった結果、アプリケーションサーバをすぐに増設できるようになりました。また、インデックスファイルを各アプリケーションサーバに配置するための、巨大なEBSボリュームが不要になりました。
これにより、このアプリケーションサーバをKubernetes上で動かすことが従来よりも簡単になりました。将来的にこのアプリケーションサーバをKubernetes上で動かすことで、スケールアウト・スケールインもしやすくなると考えています。
可用性
インデキシングサーバをElasticsearchクラスタに置き換えることで、インデキシング速度が速くなりました。また、インデックスファイルの同期が不要になったため、実際にその課題を検索できるようになるまでの時間は更に短縮されました。
インデックスファイルの同期がなくなったため、同期の失敗による、ユーザーからの検索リクエスト失敗も起こらなくなりました。この問題については度々ユーザーからお問い合わせ頂いていたのですが、サポートチームからも問い合わせが減ったと報告を受けています。
また、Elasticsearchクラスタを3 AZ構成にし、1個以上のレプリカを用意することで、インデックスファイルの破損・復旧に関する問題がほぼなくなりました。
ハードウェアコスト
インデックスファイルを同期するためのAZ間通信の費用がかからなくなりました。また、各アプリケーションサーバにアタッチしていた巨大なEBSボリュームの費用がかからなくなりました。これにより、新しく構築したElasticsearchクラスタの費用を差し引いても、1ヶ月あたり50万円以上のコスト削減になりました。
運用コスト
インデックスファイルの同期がなくなったため、手作業での復旧作業が不要になりました。
また、もしも万が一、Elasticsearchクラスタが全損して作り直すことになったとしても、bulk indexingツールで高速に作り直せるようになりました。
その他のメリット
その他のメリットとしては、長年塩漬けにされていた検索機能の仕様が、ドキュメント化されたことも大きかったです。コードも整理され、今後の機能追加・改善が容易になりました。
今後の課題
今後の課題としては、実装に関するものと、プロジェクトに関するものがあります。
性能に関する課題
性能面では、検索が従来の実装よりも遅くなるケースが見つかっています。極端に重い検索クエリが実行されると、同じ時間帯に実行された他の検索クエリもそれに引きずられて遅くなるようです。
従来は各アプリケーションサーバにインデックスファイルを配置していたため、重い検索クエリがあっても、影響範囲はそのアプリケーションサーバに閉じていました。しかし、新しいシステムでは、重い検索クエリが実行されると、Elasticsearchクラスタの検索スレッドプールがそれらに専有されることがあるようです。これはCloudWatchのThreadpoolSearchQueueメトリック(検索スレッドプール内にキューされるタスク数)で確認できました。
対策としては、重い検索クエリを特定し、その原因を1つずつ解決していきたいと考えています。
プロジェクトに関する課題
今回は、SREと開発者でプロジェクトチームを組みました。その結果、お互いの得意分野を生かして無事にプロジェクトを完了させることができました。
ただ今回の場合、実装よりも、実運用に載せるまでの作業に時間がかかり、プロジェクトの最後の約2ヶ月間は開発者の手が空いてしまいました。実運用に載せるまでの作業としては、以下のようなものがありました。
- 運用手順の作成、監視設定の作成、およびそのためのツールの動作確認
- 並行稼動開始・終了時のリリース手順書の作成、およびリリース作業
- 並行稼動中のログ、メトリック確認
このあたりの作業については、インフラ側の事前知識が必要で、開発者とうまく分担できませんでした。そのため、今回のプロジェクトの後半は、開発者には他の改善活動(ミドルウェアのアップグレードなど)に取り組んでもらっていました。
SREと開発者でプロジェクトチームを組む場合、開発者にもインフラ側の作業に入ってもらうべきかは難しい問題だと思いました。もちろん、開発者にも協力してもらえたほうがプロジェクトの完了は早くなりますが、専門領域が違うので必ずしもモチベーションが上がるとは限りません。このようなプロジェクトの進め方は今後の課題と考えています。
まとめ
今回の記事では、ヌーラボにおけるSREの活動事例をご紹介しました。また、開発者とSREが一緒のプロジェクトチームで働く、ヌーラボのSRE課の体制についてもご紹介しました。
長年使われてきたサービスを、少しずつではありますが、このように改善しています。今回の記事が、ヌーラボでのSREの仕事についてイメージするための助けになれば幸いです。
ちなみに、私は前職ではアプリケーション開発を担当しており、約2年半前にヌーラボに転職した際にSREになりました。ヌーラボには今回のように、SREとして働きつつ、開発者としての経験を活かすことができるプロジェクトもあります。
ヌーラボでのSREの仕事に興味がある方は、ぜひ「ヌーラバーの話を聞いてみたい」からお問い合わせください。

