こんにちは、Backlog SREチームのmuziです。
この記事は SRE Advent Calendar 2019 の10日目、およびBacklog Play化プロジェクトブログの番外編です。
先日のブログ記事「SREは大規模なリプレイスプロジェクトで発生した様々な問題にどう取り組んだか【Backlog Play 化プロジェクト】」の後半では、Play化プロジェクトの終了後に、開発チーム自身によるオンコール対応の取り組みを始めたことを軽くご紹介しました。
私を含むBacklogのSREチームは、このオンコール対応を助けるためのアラート通知システムを作り、開発者なら誰でも使える形で提供しています。この記事では、前回のブログ記事では書ききれなかった、このシステムの詳細をご紹介します。
同じような問題意識を抱えていて、これからオンコール対応を見直したい、と考えているSREや開発者の参考になれば幸いです。
目次
新しいオンコール体制の概要
元々、Backlogではインフラとアプリの両方についてSREがオンコール対応を行っていました。アラートの一次対応と、再起動などのワークアラウンドをSREが実施し、それでも解決できない場合のみ開発者にエスカレーションしていました。
しかし現在は、アプリケーションの障害については、開発チーム自身が対応できるようにオンコール体制を見直しました。今年の4月から準備を始め、8月から現在の体制での運用を開始しました。すでにオンコールローテーションは一周し、全開発者が一度はオンコール対応を経験した状態になっています。
このような経緯のため、いきなりすべて開発者に任せることはせず、最初は以下の形で導入しています。
- 平日の昼間(10時〜17時)のみ開発者にオンコール対応を担当してもらい、それ以外は従来通りにSREが担当する
- 開発者は2人一組で、1週間ずつ担当する
- その担当期間中は、開発者はオンコール対応と原因調査を再優先する
- 開発への影響を小さくするため、なるべく違う開発チームのメンバーで組を作る
- 頻度の高いオンコール対応をSREがマニュアル化およびツール化して、開発者への事前研修を行う
- 少しでも対応に迷ったら、開発者はすぐSREを呼んで良いことを周知する
オンコール対応を支えるアラート通知システム
ここからは、このオンコール体制を始めるにあたって実装した、アラート通知システムについて詳しくご紹介します。
アラート通知システムの全体像
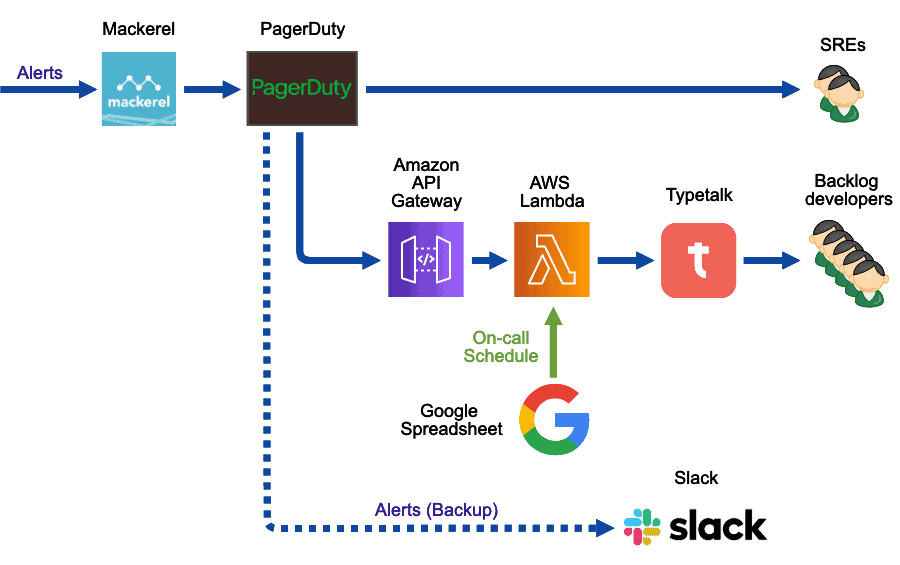 アラート通知システムの全体像
アラート通知システムの全体像
こちらが今回ご紹介するシステムの全体像です。
MackerelとPagerDutyは、SREのオンコール対応のために以前から使っていました。また、チャットツール(Typetalk)に障害が発生した場合のバックアップとしてSlackを使っていました。
今回のオンコール体制変更にあたって新たに追加したのは、図中のAmazon API GatewayからTypetalkまでの範囲です。また、MackerelとPagerDutyについても、いくつか設定の見直しを行いました。
ちなみに、この図では、アプリ監視に関係しないアラート通知は省略しています。例えば、インフラの監視にはNagiosも併用しているのですが、今回のブログ記事では省略します。
アプリケーションに関するアラートのみを開発者に通知する
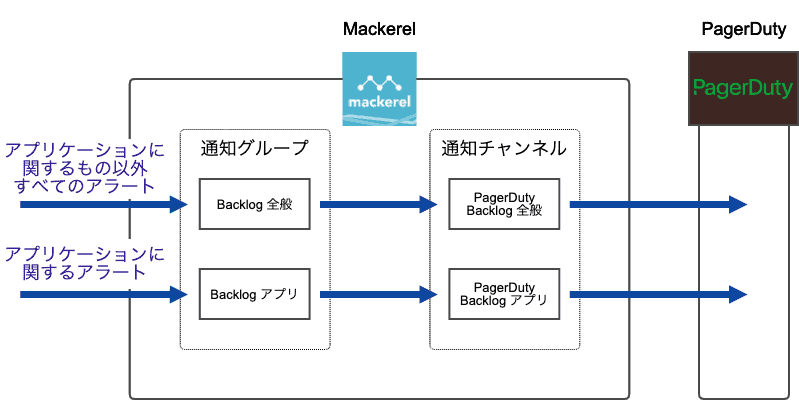 Mackerelの設定
Mackerelの設定
まずMackerelの設定の見直しについて。
元々、Backlogに関するアラートは、基本的に1個の通知グループにまとめていました。この通知グループを、PagerDutyに通知するための通知チャンネルと関連付けていました。
オンコール体制の見直しにあたり、まず最初に、この通知グループと通知チャンネルを、「アプリケーションに関するアラート」用と「それ以外のアラート」用に分けました。そして、既存のアラートをこのいずれかに分類しました。
分類の基準は、「開発者がそのアラートを受け取ったときに何らかのアクションを取れるかどうか」としました。例えば、アプリケーションが動いているEC2インスタンスの障害は、アプリケーションに関係しています。しかし、SREがアクションを取る必要があるため、上記の「アプリケーションに関するアラート」には含めませんでした。
平日の昼間は開発者に通知し、それ以外は SRE に通知する
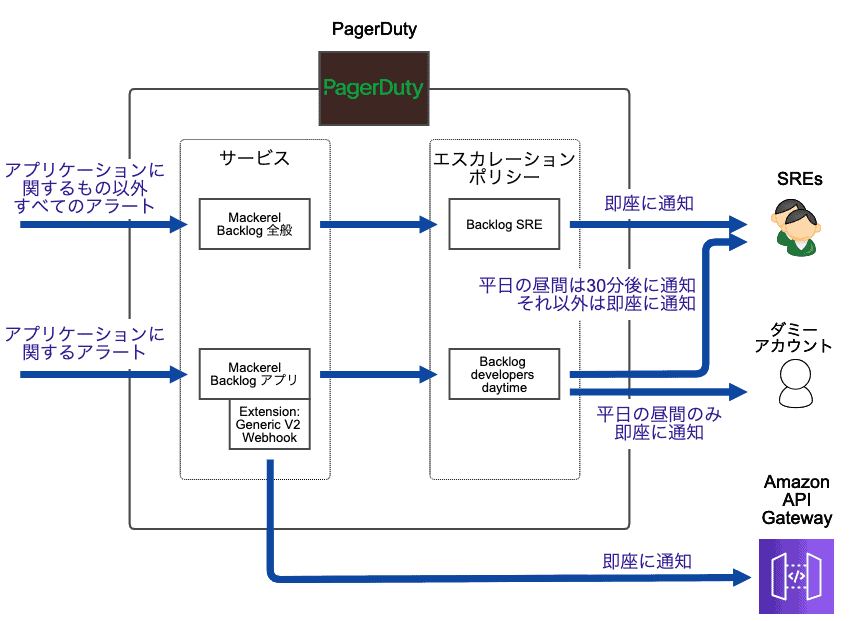 PagerDutyの設定
PagerDutyの設定
Backlog SREはPagerDutyを使っています。しかし開発者へのアラートの通知は、Webhookを経由して、弊社でサービス提供しているチャットツールのTypetalkで行うことにしました。
PagerDutyはオンコールローテーションを設定する機能(On-Call Rotations and Schedules)を持っているので、開発チーム内のローテーションもこの機能で設定する、という選択肢はありました。しかし、以下の理由でPagerDutyは使いませんでした。
- 通知するのは平日昼間だけなので、PagerDutyの豊富な通知機能の必要性は低い
- 自社でTypetalkを開発している関係で、開発者のチャットへの応答は速い
- 新しいオンコール体制が定着するかわからない段階で、開発者全員分のPagerDutyアカウントを購入するのは難しかった
PagerDutyの設定については、以下の見直しを行いました。
まず、Mackerelと同様に、サービス(PagerDutyの概念)をアプリケーションに関するものとそれ以外で分けました。アプリケーションに関するサービス(図中の「Mackerel Backlogアプリ」)にExtensionを設定し、後述するAmazon API GatewayにWebhookを送信する状態にしました。
そしてもう1点、アプリケーションに関するアラートは、開発者が30分以内に解決できなかった場合に限り、自動的にSREへエスカレーションするように設定しました。この設定は以下の方法で実現できました。
- スケジュールを以下の設定で作る
- ユーザー: ダミーアカウント(実際は誰もログインしないアカウント)1名のみ
- 期間: 月〜金の10:00〜17:00
- エスカレーションポリシー(図中の「Backlog developers daytime」)を以下の設定で作る
- 最初の通知先: 手順1で作ったスケジュール
- 次の通知先: SREのアカウント
- 最初の通知先から次の通知先へのエスカレーション: 30分後
- アプリケーションに関するサービスに、手順2で作ったエスカレーションポリシーを設定する
SREへの通知を30分遅らせるためには、どうしてもダミーアカウントが必要でした。PagerDutyの仕様上、ユーザーが0名のスケジュールは作れず、かといってここに実在するユーザーを指定すると、その人にアプリケーションに関するアラートすべてが通知されてしまうためです。
なお、現時点では開発者がオンコール対応にまだ慣れていないため、この設定は有効にしていません。つまり、SREもアプリケーションに関するアラートを受け取っています。しかし、開発者が対応できている限りは作業を横取りせず、お任せするようにしています。
オンコール担当者のみに向けてチャットツールでメンションする
 AWS Lambdaによるメンションの追加
AWS Lambdaによるメンションの追加
先ほど、開発者へのアラートの通知はチャットツールで行う、とお話ししました。今回のオンコール体制の導入にあたり、以下の2つのトピック(Typetalkの用語で、チャットルームのこと)を作りました。
- Backlog App Monitoringトピック: アラートが通知されるトピック
- Backlog On-callトピック: オンコール体制全般に関して話すトピック
オンコール担当者にはアラートを即座に通知したい一方で、その他の開発者の作業は邪魔したくありません。
そこで、PagerDutyとチャットツールの間に、AWS API GatewayおよびAWS Lambdaを挟んで、ここでオンコール担当者の確認とメンションの追加を行うようにしました。オンコールローテーションはGoogle Spreadsheet上のシートで管理し、Lambda関数(図中の「pagerduty2typetalk関数」)からこれを読み取ります。
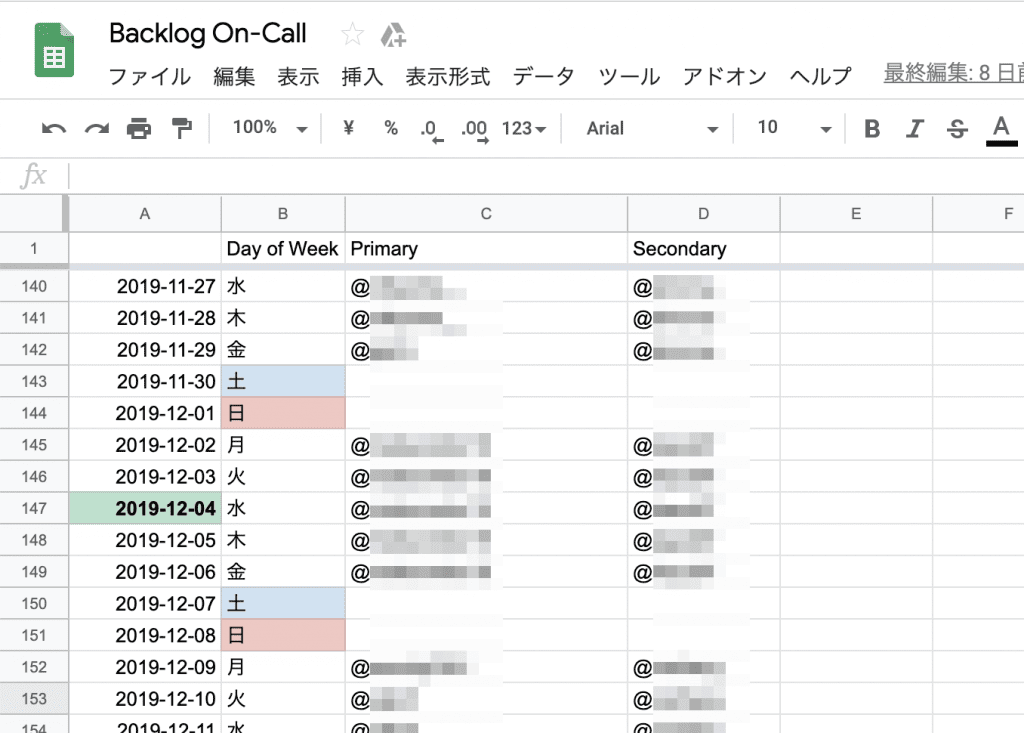 オンコールローテーションの管理シート
オンコールローテーションの管理シート
シートには、それぞれの日の、オンコール担当者のTypetalkユーザー名を記入します。オンコール担当者に急用が入った場合は、このシートを編集することで、メンション先をすぐに変更することができます。結果的に、オンコールローテーションの設定は、PagerDutyよりもかなり簡単になりました。
Typetalk上での通知は、以下のようにメンション付きで送られます。
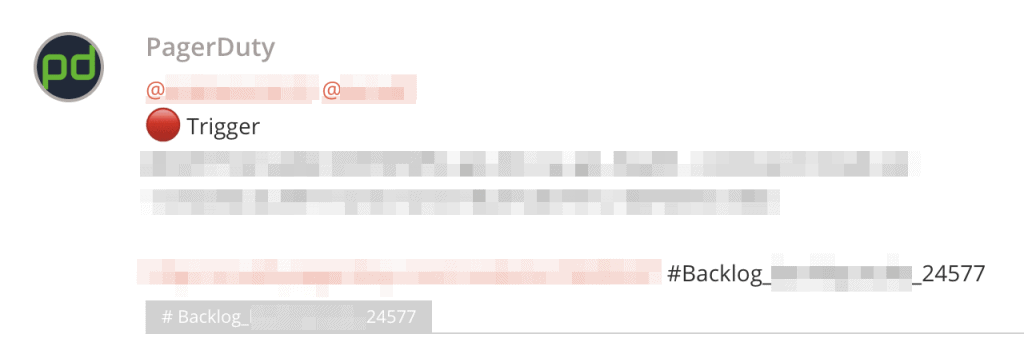 メンション付きの通知の例
メンション付きの通知の例
平日の10〜17時以外の時間は、同様のメッセージがメンションなしで送られます。Lambda関数で全く送らないようにすることも可能でしたが、時間外に送られるアラートについても開発チームがあとから確認できるようにしたほうがいいという判断から、このような実装にしました。
ハッシュタグを使ってアラートの対応状況を確認しやすくする
上記の方法では、SREがPagerDuty上で表示できるインシデント一覧を、開発者は表示することができません。これはPagerDutyの代わりにTypetalkを使う場合の弱点です(ちなみに、これはSlackのPagerDutyインテグレーションを使う場合も同様です)。
この弱点を緩和するために、今回のシステムでは、Typetalkのハッシュタグ機能を使って、同じインシデント番号が付いたアラートには同じハッシュタグを付けるようにしました。
参考: #Typetalk で「ハッシュタグ機能」が使えるようになりました(Typetalk ブログ)
複数のインシデントに関するアラートが同時に発生している場合でも、あるハッシュタグに絞ってメッセージを表示することで、各インシデントの対応状況を簡単に確認できます。また、オンコール担当者の書き込みにも同じハッシュタグを使えば、さらに対応状況を確認しやすくなります。
以下のスクリーンショットは、インシデントの発生(Trigger)から解決(Resolve)までの一例です。
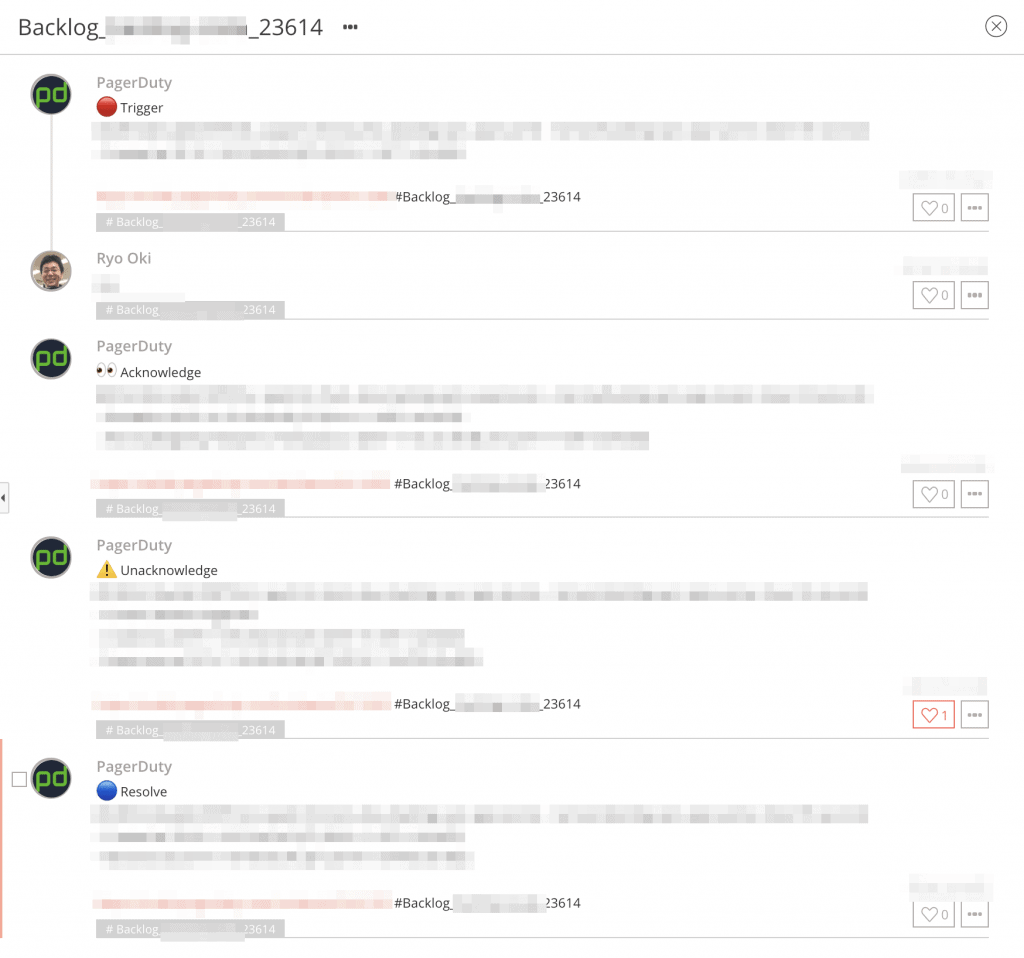 ハッシュタグを用いたアラート対応のまとめ
ハッシュタグを用いたアラート対応のまとめ
オンコールの担当日を忘れないようにする仕組み
アラートには直接関係しない部分ですが、AWS LambdaとTypetalkを使って、開発者がオンコールの担当日を忘れないようにするための通知も行っています。
まず平日の毎朝10時に、アラートが通知されるのとは別のトピック(前述の「Backlog On-callトピック」)にて、オンコール担当者にメンションしています。
 平日の朝10時に送られるメッセージ
平日の朝10時に送られるメッセージ
また、17時になったら、翌日(金曜日の場合は翌週の月曜)のオンコール担当者にメンションしています。このメッセージのなかにマニュアルへのリンクを含めて、事前チェックリストの確認を促しています。
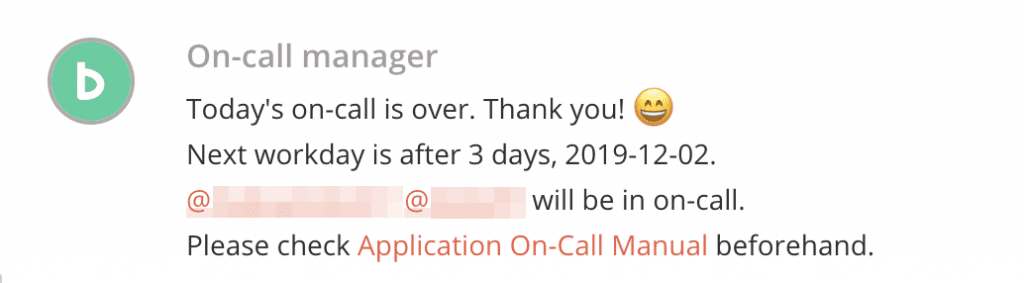 平日の夕方17時に送られるメッセージ
平日の夕方17時に送られるメッセージ
チャットツールを冗長化する
 チャットツールの冗長化
チャットツールの冗長化
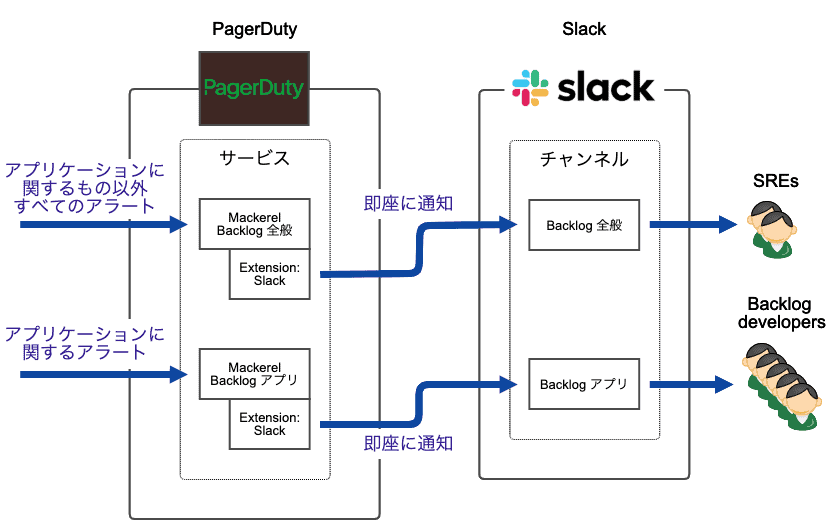
このように、Backlogでは監視のためにチャットツールをフル活用しています。そのため、Typetalkに万が一障害が発生した場合のために、そのバックアップとしてSlackも使っています。
このSlackはあくまで非常用で、普段の運用では全く使っていません。しかし、いざというときに使えないと困るため、オンコール担当者が最初に確認するチェックリストのなかに、Slack へのログイン確認も加えています。
PagerDutyのSlackインテグレーションを使って、すべてのアラートをSlackの特定チャンネルに流しています。非常用のため、Typetalk向けのような作り込みはしていません。
オンコール対応を支えるその他の仕組み
最後に、オンコール対応を支えるためにSREが用意した、アラート通知システム以外の仕組みについてもご紹介します。
まず、Play化プロジェクトで得られたノウハウを元に、以下の情報を含むオンコールマニュアルを用意しています。
- 事前準備のためのチェックリスト
- 連絡手段の確認(Typetalk でメンションが来たときにリアルタイムに通知される、など)
- 監視ツールの確認(必要なツールにログインできるか確認してもらい、アカウントがなければ発行する)
- 1週間の出社予定の確認(オンコール対応できない日は事前に代理を決めてもらう)
- オンコール対応のワークフローの説明
- アラート発生、着手、復旧、復旧後の連絡、調査、記録、記録の共有 をどのように行うか
- 影響が大きい障害のエスカレーション方法
- アラートの意味とワークアラウンド(対応手順)の一覧
加えて、オンコール対応のなかでよくある作業をJenkinsで自動化しています。例えば、以下の作業をSSH接続なしに実行できます。これらのJenkinsジョブの開始・終了は自動的にTypetalkトピックに通知され、Typetalkを見るだけで対応状況がわかるようになっています。
- サーバの再起動
- ロードバランサからの切り離し、切り戻し
- ヒープダンプの取得
- 設定ファイルの更新
これまでの感想と今後の課題
8月から約4ヶ月間、このオンコール体制を運用してみた感想ですが、いろいろなメリットがあり、導入してよかったと思っています。
まず、当初私は、開発者はオンコール対応を嫌がるのではないか、アラートが来ても素早く反応してくれないのではないか、ということを心配していました。しかし、(私にとっては)意外なことに、多くの開発者はオンコール対応をエンジョイしてくれているように見えました。これは担当期間が1週間と限られることと、新しい知識が得られることが大きかったのかもしれません。
また、開発者にアラートを直接見てもらうことで、今まで原因がわからなかった応答時間の遅延などの問題がすでにいくつか解決され、サービス品質の改善が進みました。SREよりも開発者のほうが人数が多く、コードの理解も深いため、ある開発者が発見した手がかりから、他の開発者が根本原因を見つける、といった事例もありました。
最後に、アプリケーション監視を開発チームに任せられるようになって、SREチームの負荷はかなり下がりました。これが個人的に一番大きなメリットであり、システムを改善していく一番大きなモチベーションになりました。
その一方で、今後の課題もいくつか見えてきました。
1つ目の課題は、開発チームに対するノウハウの共有です。
マニュアルは整備しましたが、たまたまアラートが発生しない週に当たった開発者は、経験から学ぶ機会が得られずにいます。また、アラート対応する機会が得られても、そこから根本原因の調査をするところにはノウハウが必要で、そこまで実践できる開発者はまだ限られています。そのようなノウハウをどう共有するかは今後の課題です。
2つ目の課題は、サービスレベルに関するアラートの整備です。
実際にオンコール体制を運用してわかったのですが、応答時間などのサービスレベルが低下していても、アプリケーションに関するアラートは飛んでいないケースがありました。いままではSREがインフラに関するアラートなども含めて経験から判断していたのですが、開発者に監視を委譲するためには、サービスレベルに関するもっとわかりやすいアラートが必要です。今後そのようなアラートを整備していきたいと思います。
まとめ
今回の記事では、Backlogの開発チームとSREチームの間で新たに導入したオンコール体制と、それを支えるアラート通知システムをご紹介しました。もし、自分たちの現場でSREと開発者の連携に課題を感じる部分がありましたら、ぜひ今回ご紹介したプラクティスを参考にしてみてください。
SRE Advent Calendar 2019 には、SREによるプラクティス紹介が多数投稿されています。明日以降の記事もぜひお楽しみに!
また、この記事はPlay化プロジェクトに関するブログシリーズの番外編でした。まだお読みになっていない方は、ぜひこちらのシリーズにも目を通してみてください。このようなオンコール体制の導入に至った背景をつかむ一助になるかと思います。
■ Play化プロジェクト連載一覧
- 時系列でみる!4年の歳月をかけてPlay Frameworkで「大規模リプレイス」した話
- 開発チームが大規模リプレイスを成功させるために取り組んだ “7つの取り組みと反省”
- Backlogのコードメンテナンス性を向上させるために気をつけたこと
- JVM上で動くWebアプリケーションがリソースを食いつぶす原因を探るためにやったこと
- SREは大規模なリプレイスプロジェクトで発生した様々な問題にどう取り組んだか
- 約4年続いた長期プロジェクトに途中参加して学んだ反省と教訓
- 4年続いた長期プロジェクトを効果的に“ふりかえる”ためにBacklogチームがやったこと

