ヌーラボの江口です。約8年間Backlogの開発を担当しており、BacklogをJavaからScala / Play Frameworkに移行するプロジェクトには最初から最後まで関わりました(プロジェクトの概要は時系列でみる!4年の歳月をかけてPlay Frameworkで「大規模リプレイス」した話をご覧ください)。
本記事では、BacklogのScala / Play Framework化プロジェクトで「Backlogのサーバーサイドを進化させる“土台”を作る」をテーマに、どのようにBacklogのアーキテクチャを設計・実装したのかご紹介します。
目次
はじめに
私は2012年の入社以来、Backlogの開発を担当しています。Backlogは10年以上続くサービスであるため、度重なる機能追加や修正を行うことで複雑化し、日頃開発をする上で様々な問題を感じていました。
今回のBacklogのScala / Play Framework化プロジェクトはスタート時点から担当する事になったため、可能な限りこれまで感じていた問題点を解決できるように設計・実装しなおすことにしました。
アーキテクチャの見直し
旧システムではコントローラー/サービス(ビジネスロジック)/DAOの三層レイヤーのアーキテクチャで実装されていました。
しかし、レイヤーごとの役割が守られないまま、場当たり的に近い形で保守・拡張され続けてきたため、以下のような問題を抱えていました。
- ビジネスロジックがコントローラーに記述されて、似たようなコードがあちこちにある。
- 逆に、ドメインオブジェクトに永続化やビューに関係するコードが記述されている。
- 一方ドメインオブジェクトにはビジネスロジックがほとんど書かれていない。いわゆるドメインモデル貧血症になっている。
このような状態だと、コードを理解するのも変更をどこに加えるか判断するのも困難です。
そこでまずビジネスロジックをビューや永続化といったコードから独立させるために、全体のアーキテクチャとしてオニオンアーキテクチャを採用しました。
オニオンアーキテクチャでは、ドメインレイヤーが依存関係の中心となるため、ユーザーインターフェイス(ビュー)・インフラストラクチャからの直接的な依存を無くし、結合度を下げることができます。
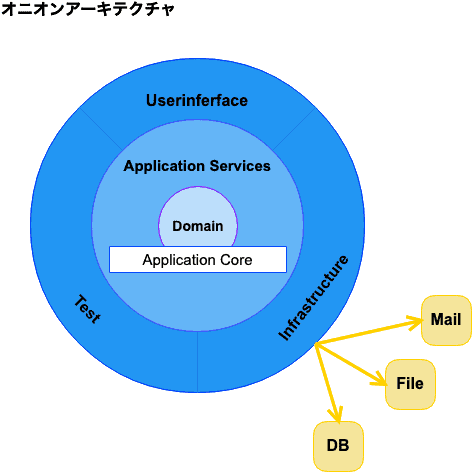
さらに、各レイヤーはそれぞれsbtのサブプロジェクトとして分割することで、コードを適切なレイヤーに置くことをある程度強制できるようにしました。例えばドメインレイヤーにDBやUserinferfaceに関するコードを書こうとしても、コンパイル時にエラーとなるので書くことはできません。
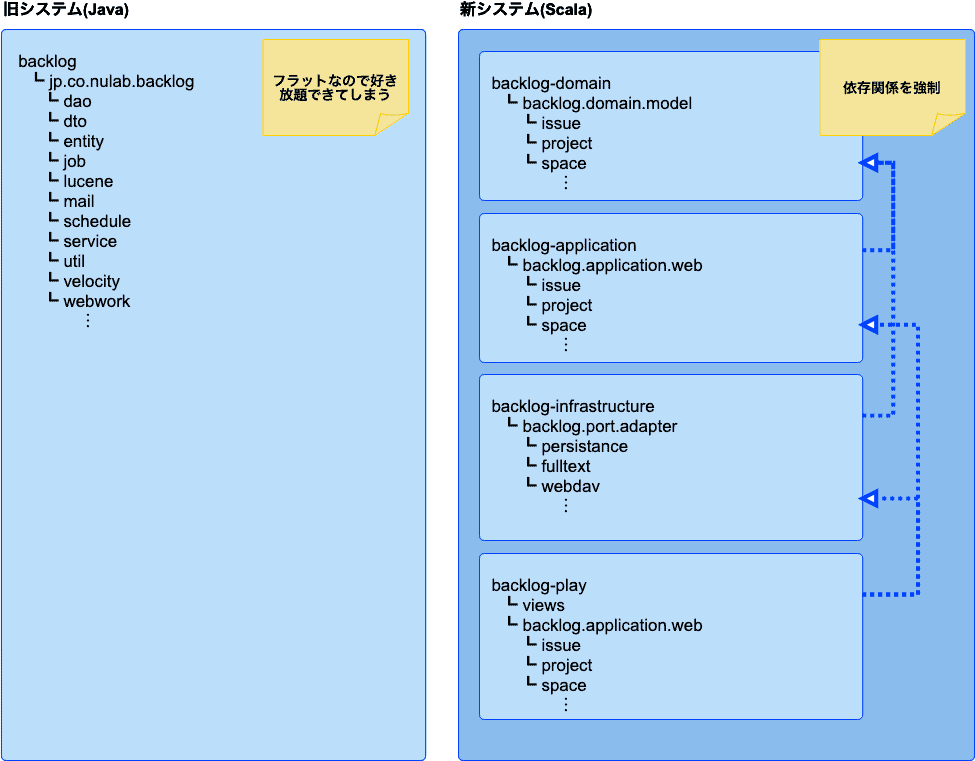 旧システム(Java)と新システム(Scala)のプロジェクト構成の違い
旧システム(Java)と新システム(Scala)のプロジェクト構成の違い
各サブプロジェクトの役割
domainサブプロジェクトは純粋なビジネスロジックのみを置くようにするために、可能な限りフレームワークやライブラリに依存しないように設定しています。
ドメインオブジェクトをRepositoryから取り出す場合、一旦RecordクラスとしてDBから取り出した後、プリミティブな値やXML、Jsonは適切なエンティティやバリューオブジェクトに変換してドメインオブジェクトとして返しています。
Scalaのcaseクラスでは状態を変更したオブジェクトを生成できるcopyメソッドが自動的に追加されます。しかし、これをドメインレイヤー外で乱用するのはビジネスロジックの流失につながるため、オブジェクトの状態を変更する操作には適切な名前のメソッドを追加してそれを使用するように気をつけています。
applicationサブプロジェクトでは以下のような処理を行っています。
- エンドポイントごとに決まっている操作可能なユーザー権限の判定
- DBトランザクションの制御
- 必要なドメインモデルの呼び出し
infrastructureサブプロジェクトにはDB、Amazon S3、全文検索などの各種外部システムなどの呼び出しに必要な実装が置かれています。
サブプロジェクトでは以下のような処理を行っています。
- クライアントから受け取ったパラメーターを必要なクラスに変換してアプリケーションサービスに渡す
- アプリケーションサービスが返すオブジェクト使ってビュー(HTML/JSONなど)に変換してクライアントに返す
具体的にリクエストを受けてからレスポンスを返す流れは次のようになります。
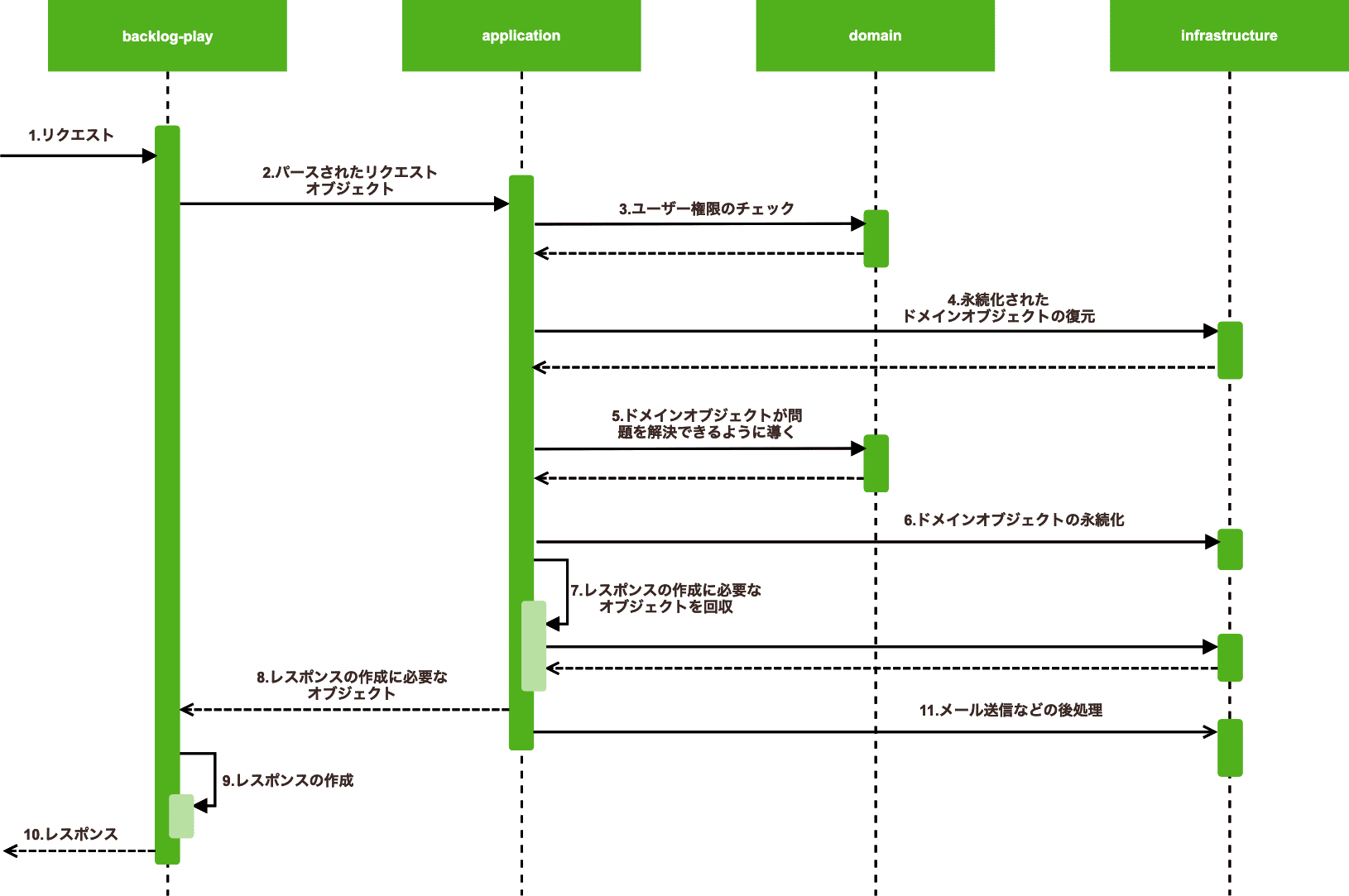
- 1. クライアントからリクエストを受ける
- 2. リクエストをオブジェクトにパース、値の型チェック・バリデーションを行う
- 3. ユーザーがエンドポイントにアクセスする権限があるかチェックする
- 4〜6. エンドポイントに定義されたユースケースに基づき、ドメインオブジェクトが問題を解決できるように導く
- 7. レスポンスの作成に必要なオブジェクトをDBなどからすべて回収する
- 9〜10. HTML、JSONなどのレスポンスデータを生成してクライアントに返す
- 11. 必要があればメール送信、全文検索インデックスの更新などの後処理を非同期で行う
連携システムを疎結合にする
Backlogではユーザーの手で操作が行われた時に、サーバー側では様々な処理が行われています。
例えば、課題を追加したときには全文検索用インデックスの更新、メールの送信、Webhookの送信、Typetalkなどの外部システムとの連携処理などが行われています。
直接これらのシステムと依存するコードをアプリケーションサービスに記述するとそのコードが肥大し複雑化してしまうため、Akka Event Streamを利用しました。
アプリケーションサービスではイベントの発行だけを行い、必要な連携処理は各種サービス自体がイベントを検知して処理します。
そのためイベント発行元のアプリケーションサービスのコードに影響を与えること無く、各連携システムを追加したり変更できたりするようになりました。
そのほかの改善
アプリケーションやDBで問題が発生した場合、旧システムでは問題の発生時点のタイムスタンプとログに出力された例外で原因となったリクエストを推測する必要がありました。
これを改善しリクエストを追跡するために、AWS ALBの発行するX-Amzn-Trace-IdをアプリケーションとSQLのログに埋め込むようにして関連するログやアクセス、SQLを見つけやすくなりました。
旧システムではメール送信など定期実行されるバッチ処理と、様々なジョブのキューを処理するするコードが同一のコード上に実装されていました。
Play化にあたり独立したアプリケーションとして実装しなおし、アプリケーション更新などの再起動時に適切にシャットダウンされるようにGraceful Shutdown機能を追加しました。
「Backlogのサーバーサイドを進化させる“土台”を作る」ために、時間はかかりましたが、複雑化しメンテナンス性の下がったコードを一旦整理することができました。
ただ、コードを書き換えるだけでは改善できなかった問題、一部の機能・SQLが原因でBacklog全体に影響が出てしまうなど、改善が必要な点がまだ残っています。
より快適にBacklogを利用していただけるようにマイクロサービス化の検討など、インフラも含めて今後も改善を続けていきますのでよろしくお願いいたします。
■ Play化プロジェクト連載一覧
Play化プロジェクトメンバーが執筆した他の記事もぜひご覧ください。
- 開発チームが大規模リプレイスを成功させるために取り組んだ “7つの取り組みと反省”
- Backlogのコードメンテナンス性を向上させるために気をつけたこと
- JVM上で動くWebアプリケーションがリソースを食いつぶす原因を探るためにやったこと
- SREは大規模なリプレイスプロジェクトで発生した様々な問題にどう取り組んだか
- 大規模プロジェクトに途中参加して感じたこと
- 長期プロジェクトを効果的に “ふりかえる”ためにBacklogチームでやったこと

