ヌーラボでScalaを書くRubyistの谷本です。ヌーラボでは、Backlogの開発を担当しており、最近ではBacklogをJavaからScala / Play Frameworkに移行するプロジェクトのメンバーでした。
BacklogのPlay化プロジェクトでは、OutOfMemorryError(以下、OOM)の発生やCPU使用率とロードアベレージが上がったままという、Java Virtual Machine(以下、JVM)上で動くBacklogのパフォーマンスに関する問題に対処すべく、何度かHeap/Thread dumpを見る機会がありました。
私がPlay化プロジェクトで取り組んだパフォーマンス改善の知見や経験をもとに、本記事では「JVMで起こったパフォーマンスの問題の切り分け方」についてお届けします。
目次
はじめに
本番環境でしばらく動かしていると、コード自体は正しく実行できるけど、ある特徴を持ったデータと実装方法がマッチせずOutOfMemorryError(以下、OOM)が発生したり、CPU使用率とロードアベレージが上がったままになったりすることがあります。
BacklogのPlay化プロジェクトでは、そういったパフォーマンスの問題の原因調査のために何度かHeap/Thread dumpを見る機会があり、その都度、どうすれば切り分けれるか考えたり勉強したりしました。
数年前にJVMの仕事をはじめたときや、Backlogの開発に携わり始めたときを振り返ってみると、こうしたパフォーマンスの問題の切り分け方を知っていれば、もっと素早く解決できただろうと感じます。
そこで、この記事では、数年前の自分のように「GCやHeap領域の名前や役割はなんとなく知っているけど、Heap/Thread dumpで情報がたくさん出てきて、何に注目すれば問題の解決につながるのかよくわからない」と感じている人に向けて、どういったことに注目して調査したのかについてご紹介します。
OOM発生時とCPU使用率の上昇時のそれぞれで、いくつかの注目する点と簡単な再現コードを使った問題の切り分け例がありますので、お好きなところからお読みください。
OOMの原因を探る
OOMが起きる原因は、Oracleのドキュメントにあるように色々な原因があります。
おそらく、起動後しばらく安定して動いている状態であれば、クラスメタデータが読み込み終わっており、Metaspace由来などのOOMは起きづらく、OOMの原因はHeap領域由来のものが多いでしょう。 Backlogで起こるOOMも、大半がHeap由来のGC Overhead limit exceededでした。
そこで、今回はGC Overhead limit exceededに絞って説明します。
なお、OOM発生時にHeap dumpが出力される起動オプションを設定をしておきましょう。これがないとOOMが起こってもHeap dumpがなく切り分けが進みません。
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/your/dumping/path
注目する点1. なぜ、OOMが発生したのか
まず、エラーのメッセージを手がかりに、どういうことが起こったからOOMが発生したのかを考えます。
GC Overhead limit exceededは、Full GCを何回もして掃除しているけど空き領域がほぼ確保できない状態が続いていることを表すエラーです。つまり、“処理を進めるためにはHeap領域が足りない状態だが、参照が残っていてHeap領域がFull GCでもほぼ空かない状態”だと言えるでしょう。
このため、参照が残っているオブジェクトがHeap領域を圧迫している理由を探せば解決できそうだと予想できます。
注目する点2. なにがHeap領域を圧迫しているか
Heap領域を圧迫しているオブジェクトを調べたいので、VisualVMやEclipse Memory Analyzer(MAT)などのツールを使いHeap dumpの中身をみて、Heap上でサイズが大きなものを探します。
ただし、Heap上でのサイズというのは少し厄介で、オブジェクトが参照している他のオブジェクトまで含めたサイズを見ないと、そのオブジェクトがGCされたときのサイズが予想しづらくなります。例えば、JavaのHashMapのインスタンス自体は48Bと小さなオブジェクトです。しかし、そのインスタンスが参照するオブジェクトが数MBあり、その参照されているオブジェクトが他から参照されていなければ、このHashMapのインスタンスがGCされると数MBの空きができます。
MATのHistgramには、参照先まで含めたサイズを表示するRetained Heapという項目があります。Retained Heapが大きい順や、並べたとき見覚えのあるクラス名順に見ていくと、参照先が大きかったり大量にあったりするような、Heap領域を圧迫していそうなオブジェクトが見つかります。

VisualVMもインスタンスタブの中にある「保持された大きさを計算」をクリックすると同様の情報が表示できます。ちなみに、両方ともツール自体にメモリを十分に与えていないと表示できないので気を付けましょう。

注目する点3. なぜ圧迫するオブジェクトができたか
Heap領域を圧迫していそうなオブジェクトが見つかったら、それがなぜできたかを考えます。なぜを知るためには、そのオブジェクトがどういう役割のオブジェクトなのか理解して仮説をたてます。
例えば、リスト構造を表すようなオブジェクトの場合はどういう役割で使われていて、どういうときに要素が追加されるのかとか、Threadを表すオブジェクトのローカル変数の場合は、他のローカル変数の中身やスレッド名から何の処理をやっているスレッドなのかというのを理解し、どういうときにそのローカル変数は大きなものになるのかなどです。
そして、もしその仮説が成り立つなら他のオブジェクトやマシンリソースにどういう影響があるを考え、その通りになっていたのか調べ、矛盾がないか検証をします。
実際にOOMを発生させてHeap dumpを見てみる
上記の注目する点を踏まえて、実際に本番環境で後続処理が遅いときに起こった現象を参考にしたコードを実行して、OOMを発生させてみます。
実行したコードはこちらです。 簡単に説明すると、すこし大きめのオブジェクトを生成(getLargeObject)して、それを時間がかかる処理(executeHeavyTask)に渡し、それぞれは別のスレッドプールを使って実行しているというコードです。
import java.util.concurrent.Executors
import scala.concurrent.{ExecutionContext, Future}
import scala.util.Random
class LargeObject(val i: Int) {
val list = (0 to i * 10).toList
}
object OomSample {
val r = new Random
def getLargeObject(implicit executionContext: ExecutionContext): Future[LargeObject] = Future(new LargeObject(r.nextInt(1000)))
def executeHeavyTask(o: LargeObject)(implicit executionContext: ExecutionContext): Future[Int] = Future {
Thread.sleep(o.i)
o.i
}
def main(args: Array[String]): Unit = {
val ec1 = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(5))
val ec2 = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(2))
val ec3 = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(10))
while(true) {
getLargeObject(ec1)
.flatMap(executeHeavyTask(_)(ec2))(ec3)
.foreach(println)(ec3)
Thread.sleep(100)
}
}
}
コンパイルしたものを、以下のように実行して、しばらく(自分のローカルのdocker上では3分ほど)経つとOOMが発生しました。
java -Xmx128m \ -cp /root/work/scala-library-2.12.6.jar:/root/work/target/scala-2.12/classes/ \ -XX:+HeapDumpOnOutOfMemoryError \ -XX:HeapDumpPath=/root/work/ \ OomSample 1> /dev/null
まず、エラーメッセージはGC overhead limit exceededだったので、何がHeap領域を圧迫しているのか探ってみます。
MATのHistgramでRetained Heap順にすると、オブジェクトの個数のわりにThreadPoolExecutorとLinkedBlockingQueueのインスタンスが大きそうなことがわかります。
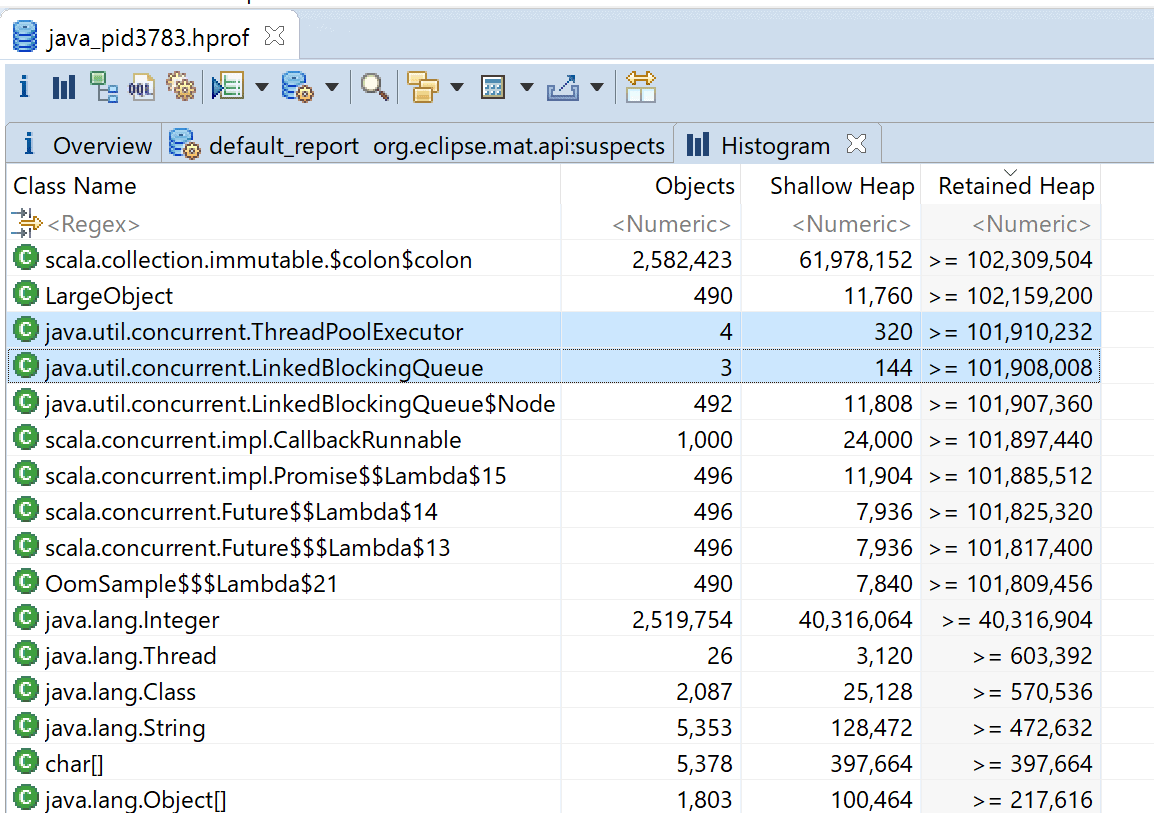
そこで、右クリックメニューのList objects > with outgoing referencesでThreadPoolExecutorとLinkedBlockingQueueのリストを表示して詳細を調べます。
大きなThreadPoolExecutorの詳細を見ると、大きなLinkedBlockingQueueを持っていることがわかります。 ThreadPoolExecutorは問題ではなくこのLinkedBlockingQueueがHeap領域を圧迫していることがわかりました。
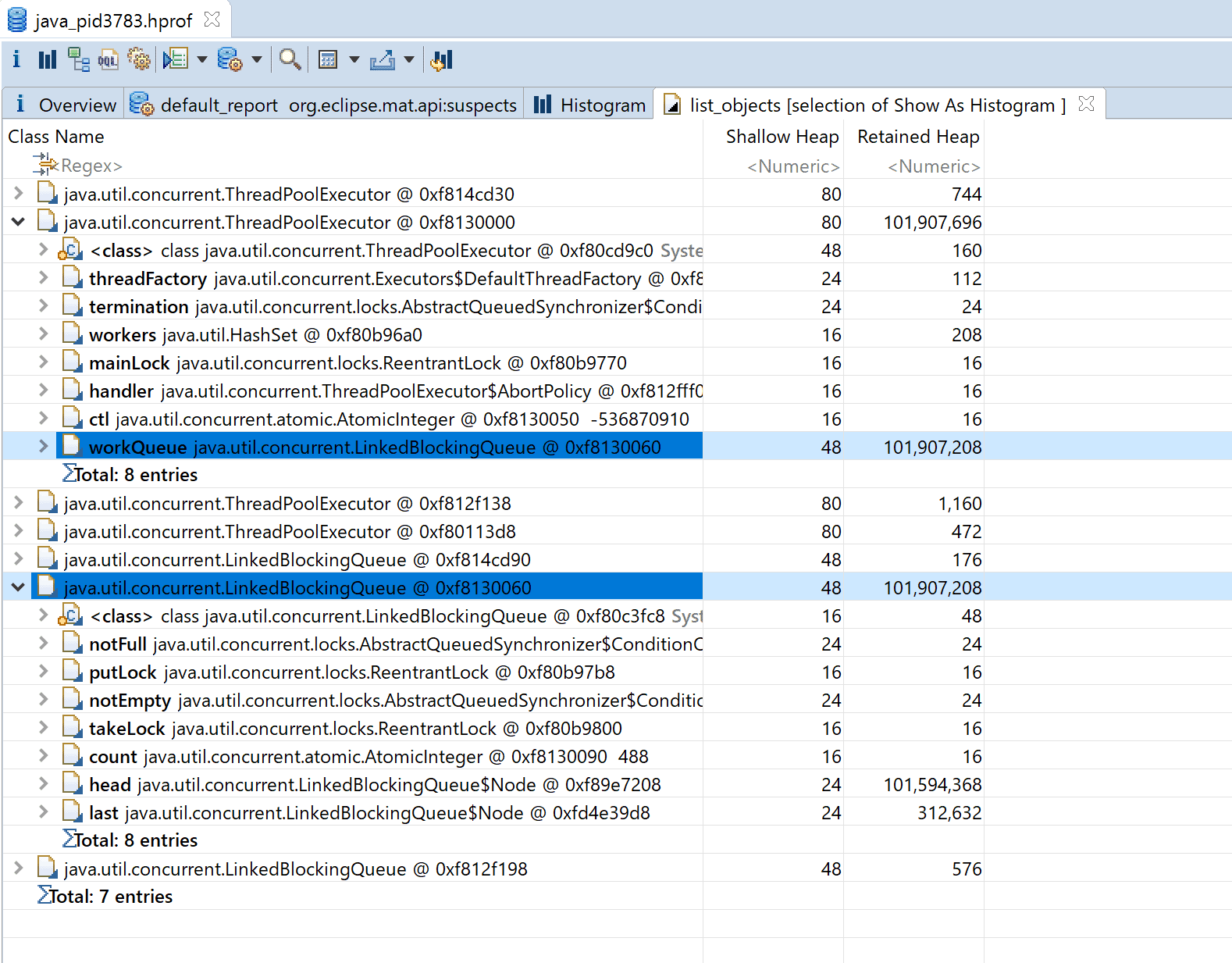
では、なぜ、Heap領域を圧迫するほど大きなLinkedBlockingQueueができたのかを考えてみます。 そもそも、この大きなLinkedBockingQueueはスレッドプールのタスクを保持するQueueです。
そして、QueueのNodeの中身をのぞいていくとLargeObjectを持っていることから、LargeObjectを使うタスクがたまっていることがわかります。
LargeObjectを使うメソッドはexecuteHeavyTaskしかいないので、executeHeavyTaskが遅いことやexecuteHeavyTaskを実行するスレッドが2つしかないことが原因で、処理が追い付かずQueueにタスクがたまり続けHeap領域を圧迫していると仮説を立てることができます。
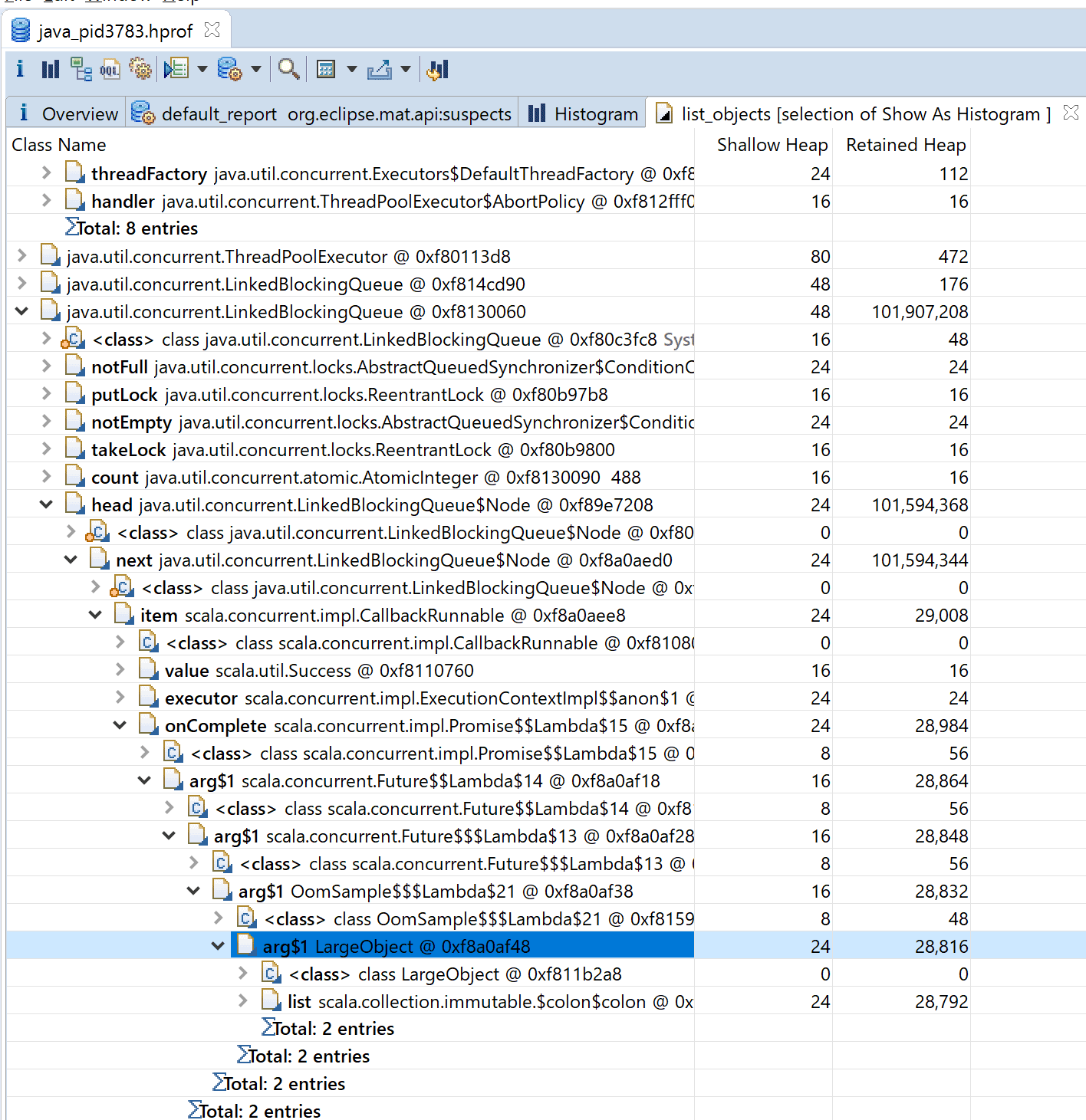
ちなみに、今回のサンプルコードはexecuteHeavyTaskのThread.sleepをコメントアウトし、時間がかからないようにするとOOMが起きなくなりました。(実際のコードもこれくらいサクッと高速化できたらうれしいのですが…)
CPU使用率の上昇の原因を探る
CPU使用率が高いこと自体は問題ありませんが、処理が追いつかずロードアベレージが上がっている場合はその限りではありません。その場合はCPU使用率が高い原因を調べる必要があります。
注目する点1. JVM自身の処理なのか自分たちのコードの実行なのか
まず、JVMのCPU使用率が上がる原因は自分たちのコード以外にもGCなどのJVMの処理で上がることがあります。OOM発生前でFull GCが頻発しているときかどうかくらいは比較的簡単に確認できるので確認してもよいと思います。
確認方法は起動オプションに-Xloggc:/your/gclog/file-path-and-format.logを指定しておけばGCログで確認できます。また、Mackerelなどの監視ツールでGCに関するメトリックスをとっていればそちらでも確認できます。
注目する点2. 何の処理を実行中にCPU使用率が高かったのか
どういった処理がCPUリソースを消費しているのかを調べます。
Oracleのブログで紹介されている手順で調べることができます。まず、top -Hを使いThreads-modeで見ると、各スレッドのCPU使用率がわかります。そこに表示されているPIDを16進数にした値がThread dump内の各スレッドのnidと対応しています。
例えば、top -Hで見たとき、以下ようなPID306のスレッドがあるとき、
306 root 20 0 2503972 88856 15696 R 62.5 2.2 1:59.22 pool-1-thread-2
306を16進数表記にすると132なので、Thread dumpを見て、nid=0x132のpool-1-thread-2が対応してるスレッドであり何を実行中なのかがわかります。
"pool-1-thread-2" #9 prio=5 os_prio=0 tid=0x00007f39d1c2f800 nid=0x132 runnable [0x00007f39c09f7000]
java.lang.Thread.State: RUNNABLE
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155)
at HighCpuSample$.$anonfun$thirdPowerOf$3(HighCpuSample.scala:8)
at HighCpuSample$$$Lambda$14/2100333990.apply$mcVI$sp(Unknown Source)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:156)
このように、top -HとThread dumpを見ることでCPU使用率が高いスレッドが行っている処理を特定できます。
注目する点3. 処理の具体的な内容は何だったのか
どの処理を実行中にCPU使用率が高かったのかがわかり、そのコードを見て明らかに問題であることがわかれば、修正して終わりになります。
しかし、実際は、CPU使用率が高いスレッドが一つではなく、いくつかのスレッドが他と比べると高い状態になっていたり、リクエストデータの特徴の違いによって同様の処理でも処理時間にばらつきがあったりします。 コードを見ただけではわからないときや確証を得られないときは、さらにHeap dumpから処理で扱っているデータを見て、処理の具体的な内容は何だったのかを確認します。
MATを使うとThreadオブジェクトの参照にローカル変数が<Java Local>という表示ででることがあるので、詳細を確認することである程度予測できます。 また、VisualVMの場合もHeap dumpについているThread dumpからローカル変数の詳細をたどることができるので、ある程度予測できます。
ただ、片方では表示できる情報がもう一方では表示できないということがあるので、わからなかったら違うツールを使って調べてみるとよいです。
実際にCPU使用率の上昇が続く状態にして原因を追ってみる
今回は、効率の悪い方法で3乗を計算して返す以下のコードでCPU使用率が高い状態が続くようにしてみます。 top -HとThread/Heap dumpをみて原因を追い、thirdPowerOfに引数に10000が与えられたときに処理に時間がかかっていると予測するところまでやってみます。
import java.util.concurrent.Executors
import scala.concurrent.{ExecutionContext, Future}
object HighCpuSample {
def thirdPowerOf(n: Int)(implicit executionContext: ExecutionContext): Future[Int] = Future {
var i = 0
(1 to n).foreach(_ => (1 to n).foreach(_ => (1 to n).foreach(_ => i = i + 1)))
i
}
def main(args: Array[String]): Unit = {
val ec = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(5))
thirdPowerOf(10000)(ec)
thirdPowerOf(10000)(ec)
thirdPowerOf(10000)(ec)
while (true) {
thirdPowerOf(100)(ec)
Thread.sleep(10)
}
}
}
コンパイルしたものを、以下のように実行します。(以下、プロセスIDが293で起動しているものとして説明します。)
java -Xmx128m \ -cp /root/work/scala-library-2.12.6.jar:/root/work/target/scala-2.12/classes/ \ -Xloggc:/root/work/gc.%p.log \ HighCpuSample
まず、Full GCが頻発していないか確認します。
root@9351b9b5ca2a:~/work# grep -i full gc.pid293.log root@9351b9b5ca2a:~/work#
今回は一回も起こっていませんので、CPU使用率が高い理由はGCは関係なさそうです。
次に、何の処理を実行中にCPU使用率が高かったのか、切り分けに必要な情報(top -H、Thread/Heap dump)を取得します。
root@9351b9b5ca2a:~/work# top -H -p293 -b -n1 && jcmd 293 Thread.print > 293.tdump && jcmd 293 GC.heap_dump /root/work/java_pid293.hprof top - 01:26:09 up 13:07, 0 users, load average: 3.58, 5.43, 6.11 Threads: 18 total, 3 running, 15 sleeping, 0 stopped, 0 zombie %Cpu(s): 44.3 us, 4.6 sy, 0.0 ni, 50.0 id, 0.6 wa, 0.0 hi, 0.5 si, 0.0 st KiB Mem : 4023320 total, 1516504 free, 989028 used, 1517788 buff/cache KiB Swap: 1048572 total, 1048572 free, 0 used. 2808916 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 306 root 20 0 2503972 88856 15696 R 62.5 2.2 1:59.22 pool-1-thread-2 305 root 20 0 2503972 88856 15696 R 56.2 2.2 1:58.40 pool-1-thread-1 307 root 20 0 2503972 88856 15696 R 43.8 2.2 2:01.17 pool-1-thread-3 297 root 20 0 2503972 88856 15696 S 6.2 2.2 0:03.02 VM Thread 308 root 20 0 2503972 88856 15696 S 6.2 2.2 0:15.77 pool-1-thread-4 309 root 20 0 2503972 88856 15696 S 6.2 2.2 0:15.74 pool-1-thread-5 293 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.00 java 294 root 20 0 2503972 88856 15696 S 0.0 2.2 0:01.51 java 295 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.31 java 296 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.33 java 298 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.00 Reference Handl 299 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.00 Finalizer 300 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.00 Signal Dispatch 301 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.24 C2 CompilerThre 302 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.18 C1 CompilerThre 303 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.00 Service Thread 304 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.12 VM Periodic Tas 326 root 20 0 2503972 88856 15696 S 0.0 2.2 0:00.05 Attach Listener 293: Heap dump file created root@9351b9b5ca2a:~/work#
top -Hの結果を見て怪しそうなスレッドのnidを特定します。 上位3スレッドが他と比べCPU使用率が高く怪しそうなので、PIDを16進数に変え、
irb(main):001:0> <<-STR.split("\n").map{|l| l.to_i.to_s(16)}
irb(main):002:0" 306 root 20 0 2503972 88856 15696 R 62.5 2.2 1:59.22 pool-1-thread-2
irb(main):003:0" 305 root 20 0 2503972 88856 15696 R 56.2 2.2 1:58.40 pool-1-thread-1
irb(main):004:0" 307 root 20 0 2503972 88856 15696 R 43.8 2.2 2:01.17 pool-1-thread-3
irb(main):005:0" STR
=> ["132", "131", "133"]
nidの値を基に各スレッドがどういう処理をしている最中だったのかを確認します。
root@9351b9b5ca2a:~/work# grep -A5 -e "nid=0x132 " -e "nid=0x131 " -e "nid=0x133 " 293.tdump
"pool-1-thread-3" #10 prio=5 os_prio=0 tid=0x00007f39d1c32800 nid=0x133 runnable [0x00007f39c08f6000]
java.lang.Thread.State: RUNNABLE
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155)
at HighCpuSample$.$anonfun$thirdPowerOf$3(HighCpuSample.scala:8)
at HighCpuSample$$$Lambda$14/2100333990.apply$mcVI$sp(Unknown Source)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:156)
--
"pool-1-thread-2" #9 prio=5 os_prio=0 tid=0x00007f39d1c2f800 nid=0x132 runnable [0x00007f39c09f7000]
java.lang.Thread.State: RUNNABLE
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155)
at HighCpuSample$.$anonfun$thirdPowerOf$3(HighCpuSample.scala:8)
at HighCpuSample$$$Lambda$14/2100333990.apply$mcVI$sp(Unknown Source)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:156)
--
"pool-1-thread-1" #8 prio=5 os_prio=0 tid=0x00007f39d1c2e000 nid=0x131 runnable [0x00007f39c0af8000]
java.lang.Thread.State: RUNNABLE
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155)
at HighCpuSample$.$anonfun$thirdPowerOf$3(HighCpuSample.scala:8)
at HighCpuSample$$$Lambda$14/2100333990.apply$mcVI$sp(Unknown Source)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:156)
すると、上位3スレッドが同様にthirdPowerOfを実行中であることがわかります。
しかし、この情報だけだと、同じスレッドプールには5スレッドあるはずなのに、この3スレッドだけが飛びぬけている理由がわかりません。
そこで、処理の具体的な内容は何だったのかを確認するため、Heap dumpを見て調べます。 VisualVMでHeap dumpを見るとサマリからThread dumpが見ることができ、そこから、具体的な処理対象が予測できるオブジェクトがないか探してみます。 コードを見ると、(1 to n)を使って範囲を表すオブジェクトを作っているので、scala.collection.immutable.Range$Inclusive#1の中身を見るとthirdPowerOfに渡された引数がわかりそうです。
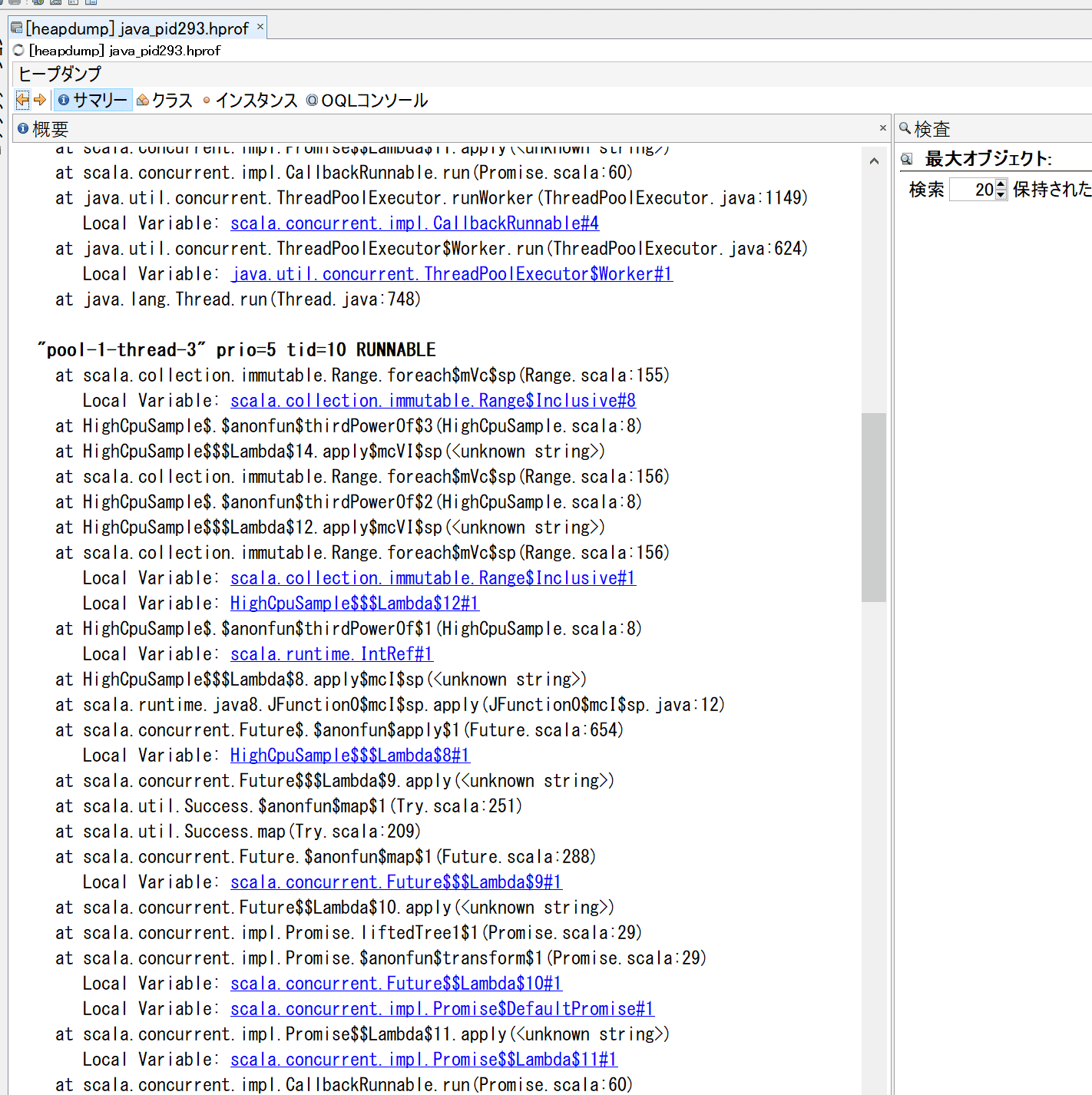
そしてこのscala.collection.immutable.Range$Inclusiveクラスのインスタンスの詳細を確認すると1から10000までの範囲を表すオブジェクトであることが確認できます。他の2スレッドも同様の値でした。
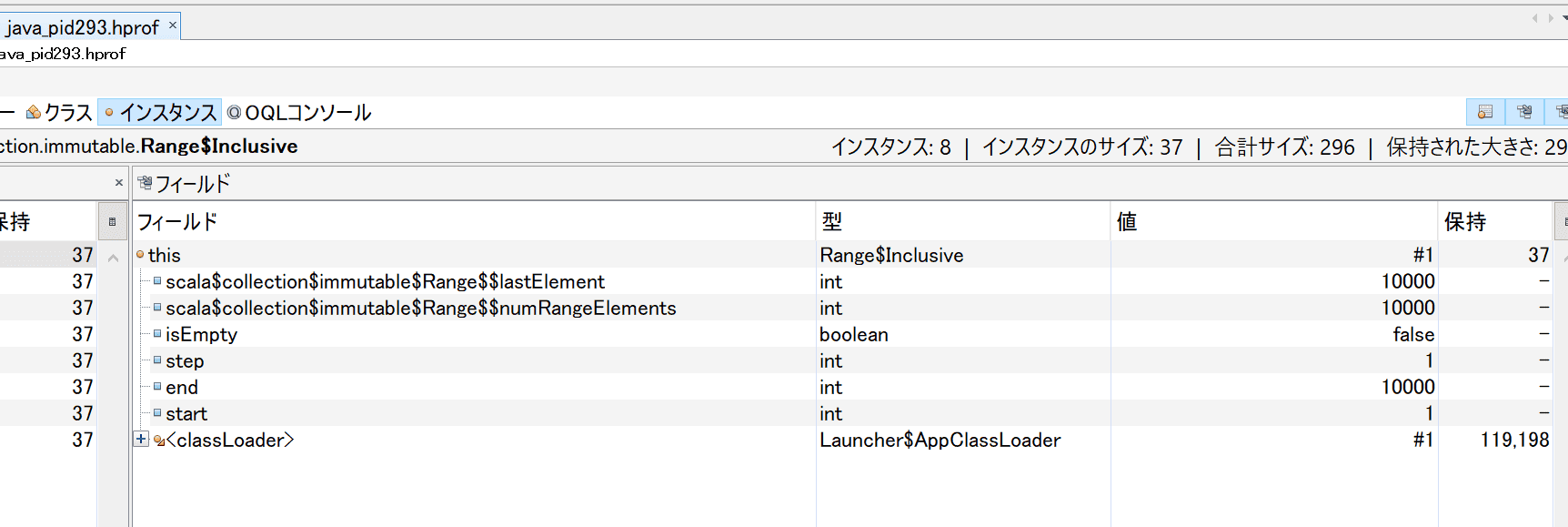
さらに、同様の処理をしているがCPU使用率が上がっていなかったスレッドのscala.collection.immutable.Range$Inclusiveクラスのインスタンスを確認すると、 1から100までの範囲を表すオブジェクトであったので、 thirdPowerOfに与えた引数が100のときは問題にならないレベルで処理ができるが、10000を与えると問題が起きるレベルになると予想できます。
まとめ
Thread/Heap dumpはJVMのその時の情報がドバっと出たもので、OOMが起こったからここが原因だと教えてくれるものではありません。しかし、理詰めで起こった現象を整理したり問題を探ったりするときに必要な情報が詰まった重要なものです。私自身は、このように考えるようになってから、何がわからないかもわからない状態から、何がわからないかわかるようになった気がして、Thread/Heap dump読むのが楽しくなりました。
最後に、ここで書いた注目する点や切り分けの順序とかは、私なりの理詰めの方法です。きっと、似ている部分はあると思いますが、人によってやり方が違ってくると思います。ですので、原因調査のやり方がわからないときに、一例として参考になれば幸いです。
■ Play化プロジェクト連載一覧
Play化プロジェクトメンバーが執筆した他の記事もぜひご覧ください。
- 時系列でみる!4年の歳月をかけてPlay Frameworkで「大規模リプレイス」した話
- 開発チームが大規模リプレイスを成功させるために取り組んだ “7つの取り組みと反省”
- Backlogのコードメンテナンス性を向上させるために気をつけたこと
- SREは大規模なリプレイスプロジェクトで発生した様々な問題にどう取り組んだか
- 大規模プロジェクトに途中参加して感じたこと
- 長期プロジェクトを効果的に “ふりかえる”ためにBacklogチームでやったこと

