Backlog SREチームのmuziです。2018年4月から2019年7月まで、BacklogをJavaからScala / Play Frameworkに移行する大規模なリプレイスプロジェクトに参加していました。
SREとして、このリプレイスにはかなりの困難が伴いました。特にBacklogのサービス安定性は大きな問題でした。
本記事では、こうした問題に対して、SREである私がどういうアプローチを取ったのか、そしてこのプロジェクトで得られた教訓を今後チームや組織全体でどのように活かそうとしているかをご紹介します。
正直言って、泥臭い話だらけの内容です。それでも、技術的負債を抱えたプロジェクトでSREが取れるアプローチの事例の一つとして、読者の参考になれば幸いです。
目次
はじめに
ヌーラボでは2015年11月から2019年7月まで、BacklogをJavaからScala / Play Frameworkに移行する、という大規模なリプレイスプロジェクト(以下、Play化プロジェクト)を行っていました。
このプロジェクトの細かい経緯については、ぜひブログ記事(4年の歳月をかけてPlay Frameworkを使ってBacklogを『大規模リプレイス』した話)をご覧ください。
このリプレイスにはかなりの困難が伴いました。特に、Backlogの主要機能(課題の表示・編集)のPlay化が完了した2018年前半から、Backlogのサービス安定性が問題になり始めました。
私はこのサービス安定性の問題を解決するために、2018年4月からプロジェクト完了まで、このプロジェクトに参加しました。
今回の記事では、このPlay化プロジェクトのなかでどういう問題が発生して、それに対してSREとしてどういうアプローチを取ったか、そしてこのプロジェクトで得られた教訓を今後Backlog全体でどう活かそうとしているか、についてお話しします。
技術的負債を抱えたプロジェクトでSREが取れるアプローチの事例として、みなさんの参考になれば幸いです。
私がPlayチームに参加するまでの状況
話の背景として、私がSREとしてPlay化プロジェクトの開発チーム(以下、Playチーム)に参加するまでの状況について触れておきたいと思います。
Play化プロジェクトが始まった2015年末から2018年にかけては、Backlogのサービス規模が大きく伸びた時期でした。有料契約スペースの導入企業数も、2017年末には6000社と、2015年の倍以上まで伸びていました(プレスリリース)。今後もさらに導入企業数を伸ばすべく、この時期にBacklogのデザインの大規模リニューアルなども行いました。
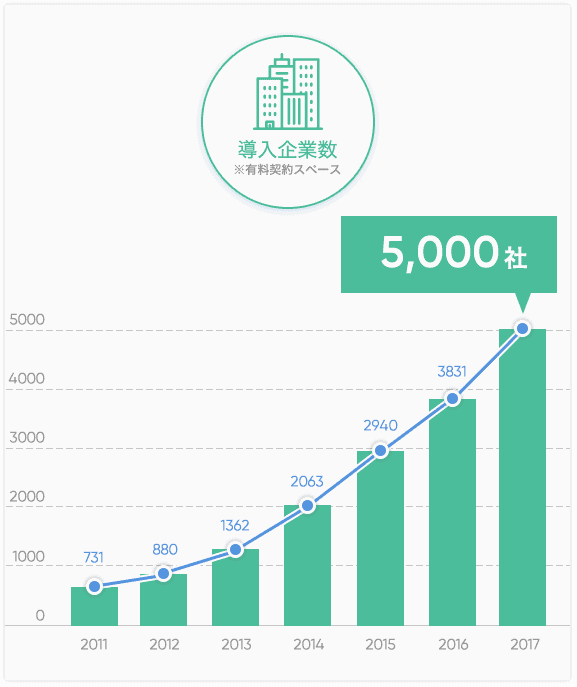 導入企業数の伸び(2017年4月時点のインフォグラフィックスより抜粋)
導入企業数の伸び(2017年4月時点のインフォグラフィックスより抜粋)
増え続けるユーザーのニーズに応えるため、Backlogの開発者もこの時期に大幅に増員されました。BacklogにSREのポジションができたのも2015年でした。
BacklogにおけるSREの歴史については、過去にSRE Lounge #5で発表しました(プレゼン資料、レポートブログ)。こちらの資料もご参考ください。
Backlogの開発者が少ない頃は、開発者がアプリケーションのオンコール対応を兼任していました。しかし、開発者が増えていくにつれて分業化が進み、私が入社した2017年頃は、インフラとアプリの両方について、SREがオンコール対応を行っていました。
当時、この作業量を測るために月次でインシデントレポートを作成していたのですが、2018年1月から明らかにアプリ関係のアラートが増加し始めました。
この増加したアラートは、主にPlay化が完了した機能に関係するアラートでした。PlayチームとSREチームで相談しながら対応を進めていたものの、Playチームは新規開発に忙しいため原因調査や解決が進まず、問題が増えるスピードに、問題を解決するスピードが追いつかないという状態でした。
当時の状況を図にするとこのようなイメージです。
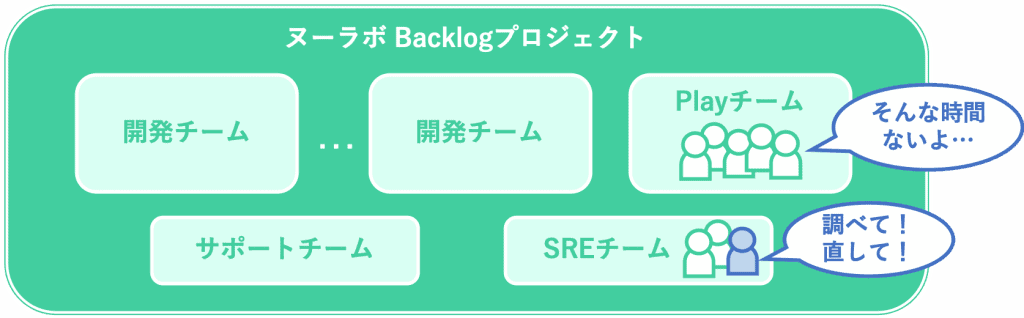 2018年3月時点のBacklogプロジェクト
2018年3月時点のBacklogプロジェクト
この状況をそのまま放置すると、いずれBacklogのサービス品質が致命的に悪化する恐れがありました。そのため、2018年4月の体制見直し時に、SREをマトリックス的に配置する組織への変更を行いました。また、SRE 1名(私のこと)がPlay化プロジェクトの専任になり、チームメンバーの一員としてアラートの原因調査や解決に取り組むことになりました。
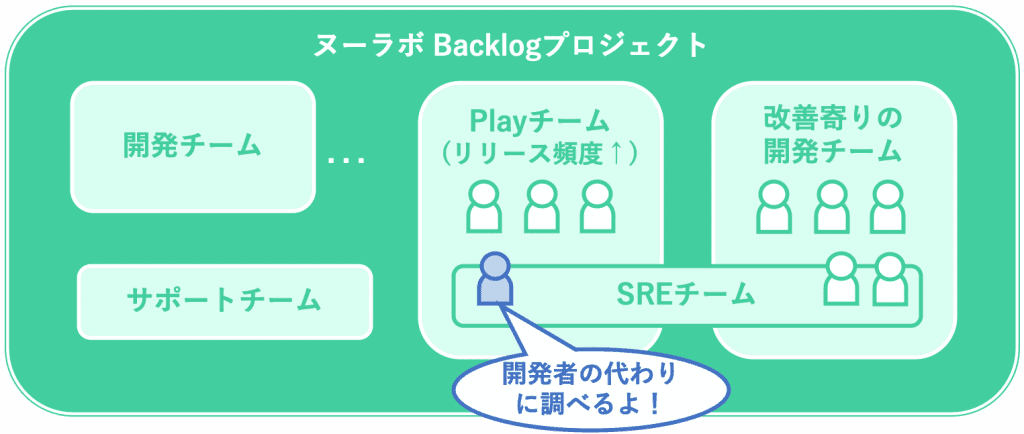 2018年4月時点のBacklogプロジェクト
2018年4月時点のBacklogプロジェクト
Playチームに参加して気づいた3つの問題
Playチームに参加した当初は、応答時間が長いリクエストを特定し、コード修正やデータベース定義の見直しによる性能改善をしたいと考えていました。アラート発生時に、CPU使用率やメモリ使用量が急上昇することが多かったためです。
しかし、Playチームメンバーの動きをチーム内から見ているうちに、開発者には手を出しづらい、SREとして解決すべき別の問題に気づき始めました。また、これらの問題の一部は、Play化の前から存在する問題のように見えました。
ログを活用できていない
私がPlayチームに参加する前から、WebサーバーおよびアプリケーションサーバーのログはKibanaで可視化されていました。また、MySQLのスロークエリログも記録されていました。しかし、これらのログが開発チームで活用されておらず、問題の解決や、問題が顕在化する前の早めの発見ができていませんでした。
その原因には、問題解決に必要なログの不足や、見るべきログを絞り込むための集計機能や通知機能の不足がありました。
また、ログレベルが適切に設定されていない、不必要なログが大量に出力されている、など、ログの活用を難しくする問題もありました。
自動テストを活用できていない
先人の努力により、Backlogのビルドは昔からJenkinsで自動化されています。Gitリポジトリへのコミット時にはユニットテストが自動実行されます。また、開発環境へのデプロイ後に、E2Eテストも自動実行されます。
しかし、このユニットテストやE2Eテストのなかに、タイミング次第で失敗するものが多数ありました。テストが日常的に失敗していたため、新しく追加したコードに問題があって失敗している場合でも、「またタイミング依存の問題だろうから」とテストの再実行を何度も繰り返している様子が見られました。
Play化がサービスレベルに与える影響がわからない
BacklogがPlay化される前から、緊急度の高い不具合についてはその都度対応してきたものの、細かい不具合には手が回らず、未解決のものが徐々に溜まってきていました。そのため、Play化されたアプリケーションが不安定でも、それは移植前からの不具合なのか、移植による不具合なのかわからない状態でした。
つまり、Play化されたアプリケーションの品質の評価が難しい状態でした。品質が低ければ機能追加を止めてでも品質を上げるべきですが、そのような判断のための基準がありませんでした。また、以前からある問題にも関わらず、Playチームの外から「Play化されたコードの品質が悪い」と見なされるケースもありました。
SREとしての取り組み
このような状況に直面し、SREとしてPlayチームに参加した私が進めたのは、日々の地道な障害対応と、そこで得られた知見に基づくシステム面での改良でした。
システム面での改良については、自分の経験から必要と感じたツールを、Playチームだけでなく、SREチームの協力も得ながら開発していきました。
地道な障害対応とテスト改善
その時点で、すでにPlay化プロジェクトは長期化していたため、アプリケーションサーバーがダウンしたり、応答時間が悪化しても、開発者には詳しく調査する余力がありませんでした。そこで、まずはそのような細かな障害をすべて記録し、原因調査を行うことから始めました。スレッドダンプやヒープダンプの取得など、調査のために必要な作業の自動化も進めました。
また、自動テストの実行結果も常に監視し、失敗したものがあればSREのほうで原因調査を行いました。タイミング依存の問題であれば、ユニットテストやE2Eテストのコードを修正しました。とにかく、開発者が自動テストを信用できる状態にすることが重要と考え、「タイミング依存の問題があったら直しますので、見つけたら必ず教えて下さい」と何度もお願いし、1つずつ問題を減らしていきました。
監視システムの改良
これまで収集してきたログを、問題解決に役立てるために、ログ調査環境の整備を行いました。
- ログ調査環境の整備
- Webサーバー(Nginx)、アプリケーションサーバー(Play Framework)、データベース(MySQL)のログに、横断検索のためのトレースIDを追加しました。また、このトレースIDを用いた横断検索のUIとして、開発者がアクセス可能なRedashを設置しました。
- データサイズや件数が多い場合のみ発生する問題が多かったため、データサイズや件数に関するログを拡充しました。これらのログに基づいて、上限値の見直しなどを進めました。
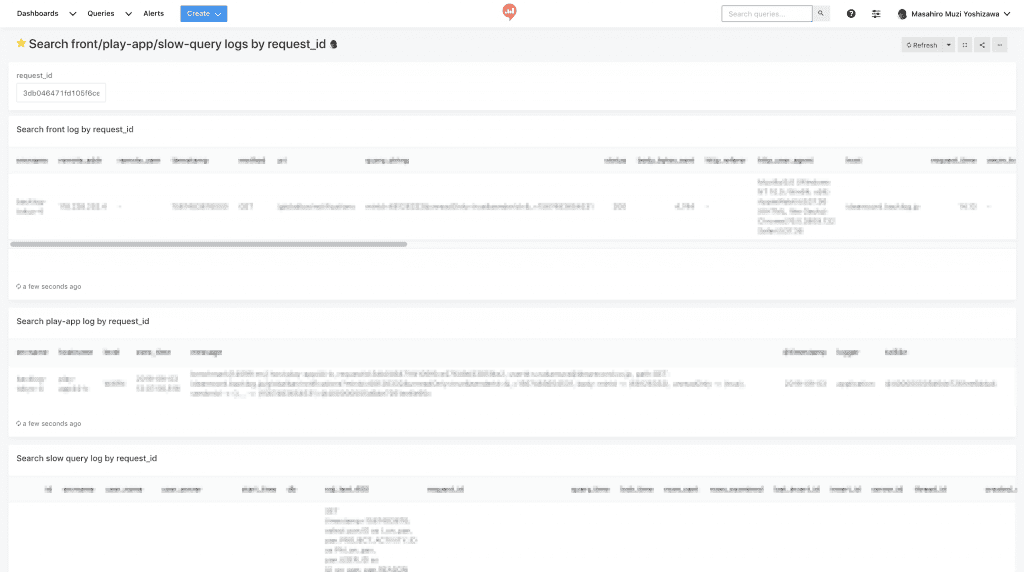 トレースIDを用いたログの横断検索
トレースIDを用いたログの横断検索
大量のログから問題を発見しやすくするための集計や通知についても、試行錯誤しつつ、いろいろなツールを開発しました。
- ログ集計の追加
- スロークエリログやエラーログをAWS Lambdaで定期的に集計し、その結果をRedashで確認できるようにしました。
- エラーログについては、特にそれぞれのエラーログについて既知/未知のラベリングを行い、リリース前後での傾向の変化を確認できるようにしました。
- アドホックに集計方法を変えたいログについては、BigTableへのログ投入も行いました。
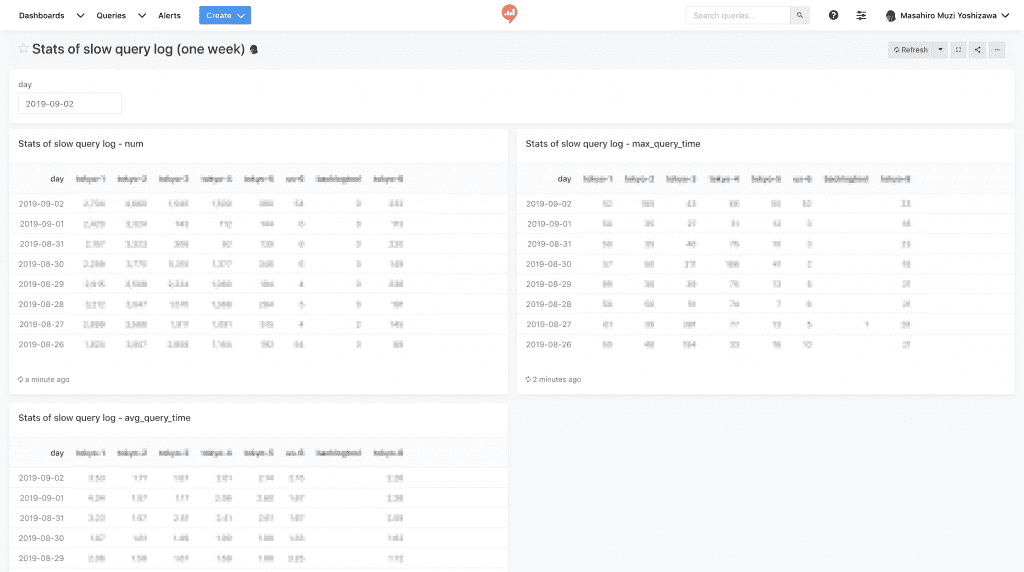 スロークエリログの統計情報の集計
スロークエリログの統計情報の集計
- ログ通知の追加
- 検索機能や集計機能を強化しても、開発者が自発的に見に行く習慣はなかなか定着しません。そこで、Typetalkボットを使って、開発者全員が入っているチャットルームに対して、未知のエラーログの集計結果を1日1回通知する機能を追加しました。
- また、緊急度の高いログについては、各開発チームのチャットルームに直接通知するように設定しました。
 未知のエラーログの件数がしきい値を超えた場合に送られる通知
未知のエラーログの件数がしきい値を超えた場合に送られる通知
自動テストの改善サイクルの確立
自動テストに関するタイミング依存の問題を一通り解決しても、またしばらくすると新たなタイミング依存の問題が発生してきました。今後は、問題を生み出した開発者自身が問題を解決するサイクルを回せるように、Jenkinsジョブの改善を進めました。
- ビルド〜自動テストに失敗した場合の通知機能の拡充(Typetalk通知)
- ビルドに失敗した場合のみ、チャットツール(Typetalk)上で、メンション付きでビルド結果を通知するようにJenkinsジョブを改善しました。
- この通知は、コミットログに含まれるメールアドレスから、Typetalk上でのユーザ名を解決するAWS Lambda関数を実装することで実現しました。この機能を実現するために、Typetalkチームの協力を得て、JenkinsのTypetalk Pluginの機能追加も行いました。
 メンション付きでのビルド結果の通知
メンション付きでのビルド結果の通知
- ビルドジョブの高速化
- 開発者の意見を聞くと、ビルド開始から自動テストの失敗までに時間がかかりすぎると、ビルド結果が無視されやすいことがわかりました。そのため、jarファイルのキャッシュを事前に用意するなどして、ビルドジョブを従来よりも高速化しました。
サービスレベル指標の可視化
Webサーバーのログにupstreamの情報を追加し、upstreamの種類(TomcatまたはPlay)ごとに応答時間やエラー率を集計できるようにしました。この集計はKibanaで行い、開発者であれば誰でも確認できるようにしました。
Backlogで確認すべきサービスレベルには、Webアプリケーションの応答時間やエラー率に加えて、バックエンドのジョブの実行時間や成功率も含まれます(バックエンドのジョブも、今回JavaからScalaに移行しました)。このようなジョブのサービスレベル指標については、AWS Lambdaで定期的に集計した結果を、Redashで可視化しました。
サービスレベルの可視化については、過去のテックブログ(サービス品質向上のためにBacklogのSREが行ってきたサービスレベル管理の取り組み)にてご紹介しました。こちらの資料も併せてご覧ください。
Play化プロジェクトの教訓
SREとしてこのプロジェクトに参加して、自分が得た教訓を率直に表すならこうなります。
- アプリケーションの障害対応は、開発者が主体となって行うべきである
- SREはアプリケーションの障害対応に必要なマニュアルの整備や、作業の自動化のみを支援し、それ以上の手助けはなるべく避けるべきである
冒頭でお話しした通り、私が入社した2017年頃は、インフラとアプリの両方についてSREがオンコール対応を行っていました。アラートの一次対応と、再起動などのワークアラウンドをSREが実施し、それでも解決できない場合のみ開発者にエスカレーションしていました。
Play化プロジェクトの最中は、私がインフラの状況と、Playチームの最新のリリース状況の両方を把握していたこともあり、アプリに関するアラートの一次対応をほぼ全て担当していました。
しかし、このように運用者と開発者の役割が分かれている環境では、たとえ運用者と開発者が同じチーム内にいても、どうしても運用者に負担が偏ります。
また、運用者が、開発者の気づかないうちにアラートを解決してしまうことで、よくある不具合について、開発者の理解がなかなか深まらないと感じていました。この1年間、開発者でも利用できるツールを色々と用意しましたが、私がSREとしてチーム内にいたこともあってか、障害対応への開発者の参加はあまり進みませんでした。
サービスが小さいうちは、少人数のSREがすべてをまかなうことも可能かと思います。しかし、現在のBacklogの規模では、アプリケーションの障害対応については開発者自身に担当してもらわない限り、SREがアプリケーションの機能追加・改善のボトルネックになってしまう。Play化プロジェクトでの経験を経て、私はそう感じました。
現在の取り組み
開発者によるオンコール対応
今後、アプリについては、開発者自身がオンコール対応できるようにするための体制作りを進めています。今年の4月から具体的な準備を開始し、8月から新しいオンコール体制の試験運用を開始しました。すでにこのローテーションは一周し、全開発者が一度はオンコール対応を経験した状態になりました。
いままで開発者にオンコール対応してもらうための体制がなかったため、いきなりすべて開発者に任せることはせず、最初は以下の形で導入しています。
- 平日の昼間(10時〜17時)のみ開発者にオンコール対応を担当してもらい、それ以外は従来通りにSREが担当する
- 開発者は2人一組で、1週間ずつ担当する
- 開発への影響を小さくするため、なるべく違う開発チームのメンバーで組を作る
- 少しでも対応に迷ったら、すぐSREを呼んで良い
試験運用に先立ち、Play化プロジェクトでの経験を生かして、アプリケーションのオンコール対応を詳しくマニュアル化し、開発者への研修を行いました。また、よくあるワークアラウンド(アプリケーションサーバーの再起動など)についてはすべてJenkinsジョブとして自動化し、サーバーへのSSH接続を不要にしました。
このオンコール対応を通じて、開発者に現在のサービス品質を理解してもらい、重要な問題への対応が早くなることを期待しています。
やはり開発者のほうがSREよりもコードの理解が深いようで、いままで原因のわからなかった問題がすでにいくつか解決され、サービス品質の改善が進んでいます。早くも手応えを感じ始めているところです。
将来的なマイクロサービス化に向けた改善
現在のBacklogは、Scala / Play Frameworkで実装されたモノリシックなWebアプリケーションにその機能の大半を含んでいます。
そのため、アプリに関する問題(例えば応答時間の悪化)が発生した場合に、根本原因となる機能の特定が難しくなっています。結果として、その問題に対する責任も宙に浮きやすくなっています。
サービス改善のサイクルを早めるために、開発チームごとの責任範囲を明確にし、開発から運用まで、その開発チームの判断で動きやすくする。そのために、今後の新機能については、できるだけ現在のモノリシックなWebアプリケーションとは独立したアプリケーションとして開発を進めています。また、既存の機能についても、複数の疎結合なWebアプリケーションに分割できるようにするための改善を進めています。
このような改善の延長として、データベースの分割を含めたマイクロサービス化を進めることで、各サービスのサービスレベル指標も作りやすくなることを期待しています。
現在はサービスレベル指標の導入が難しく、その結果エラーバジェットの導入も進んでいないのですが、将来的にはエラーバジェットを導入して、開発者とSREのやり取りを円滑に進めたいと考えています。
おわりに
今回の記事では、大規模なリプレイスプロジェクトで私たちが直面した運用上の問題と、それらの問題に対するSREの取り組みをご紹介しました。また、このプロジェクトでの教訓を活かして、私たちが現在進めている組織面およびシステム面での改善についてご紹介しました。
Backlogのように長期間続いているサービスでは、どうしても技術的負債が蓄積してしまうものです。今回の経験を活かし、安定したサービスをお客様にご提供できるよう、引き続き改善を行ってまいります。
■ Play化プロジェクト連載一覧
Play化プロジェクトメンバーが執筆した他の記事もぜひご覧ください。
- 時系列でみる!4年の歳月をかけてPlay Frameworkで「大規模リプレイス」した話
- 開発チームが大規模リプレイスを成功させるために取り組んだ “7つの取り組みと反省”
- Backlogのコードメンテナンス性を向上させるために気をつけたこと
- JVM上で動くWebアプリケーションがリソースを食いつぶす原因を探るためにやったこと
- 大規模プロジェクトに途中参加して感じたこと
- 長期プロジェクトを効果的に “ふりかえる”ためにBacklogチームでやったこと

